
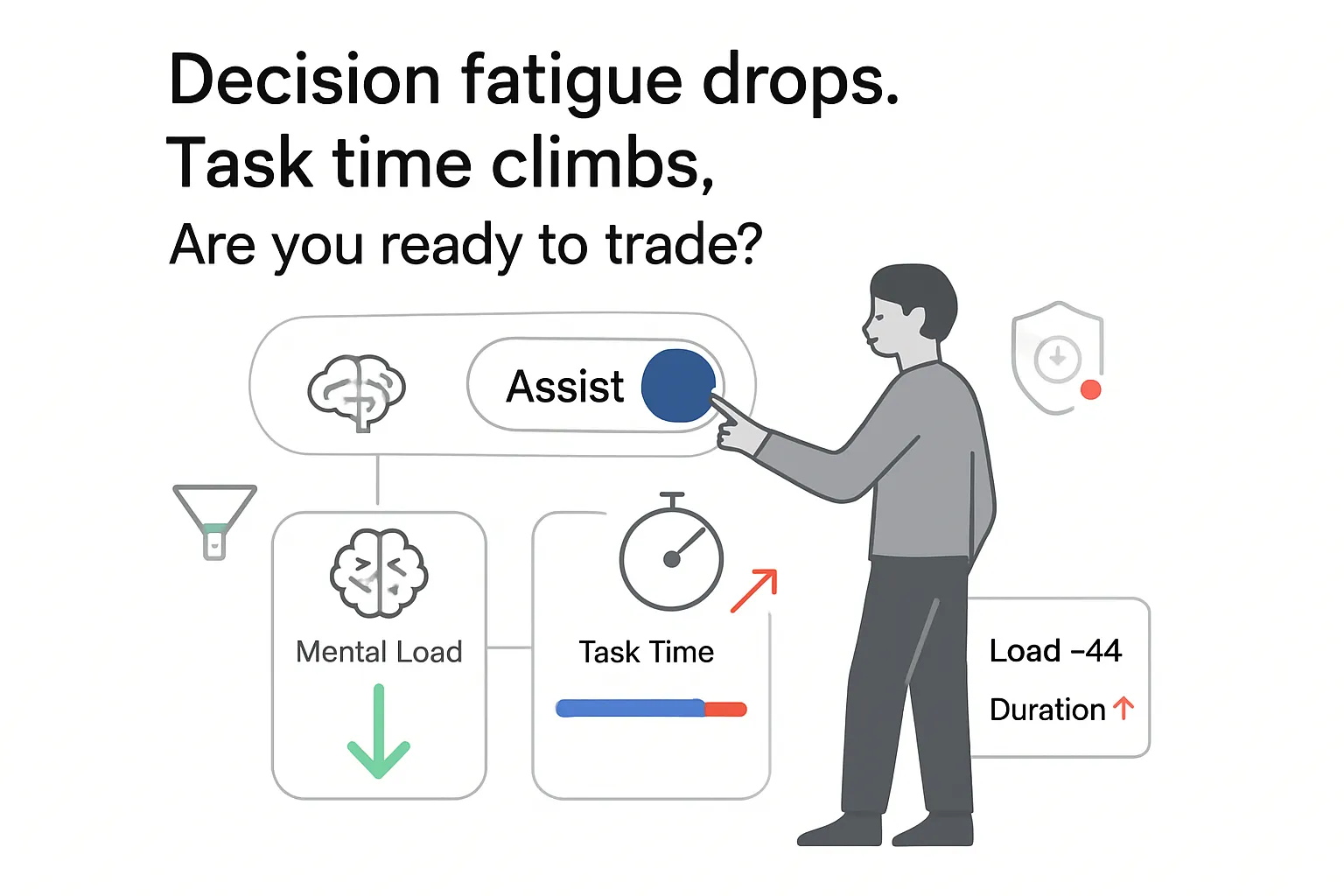
Google's Sensible Agent research prototype suggests that context-aware AR assistants that anticipate and propose next actions can lower user cognitive load and increase user preference compared with voice-only flows, at the cost of longer interaction time. This report distills the primary data and methods and outlines implications for product and marketing leaders planning AR experiences.
Sensible Agent: Executive snapshot
Google evaluated Sensible Agent, an anticipatory AR assistant that adapts modality (icons, gaze, head and hand gestures, voice) based on real-time context (gaze, hand availability, ambient noise), against a voice-initiated baseline modeled after Project Astra. Results are from a 10-person, 12-scenario study spanning restaurants, transit, grocery, museums, gym, and kitchen tasks [S1][S2]. A YouTube demo is available.
- Mental demand on the NASA Task Load Index (NASA-TLX) dropped 43.9 points (21.1 vs 65.0; p < .001) with Sensible Agent vs the voice baseline [S1][S2].
- Perceived effort was also lower (p = .0039) [S1].
- Usability measured by the System Usability Scale (SUS) was comparable, with no significant difference (p = .11) [S1][S4].
- User preference favored Sensible Agent: 6.0 vs 3.8 on a 7-point Likert scale (p = .0074) [S1][S2].
- Interaction time increased: 28.5 s vs 16.4 s, driven by a propose-then-confirm flow [S1].
Implication for marketers: AR flows that suggest next steps and accept subtle confirmations can improve comfort and perceived workload in public or noisy settings, even if completion time increases.
Method and source notes for this AR user study
- What was measured: cognitive workload (NASA-TLX), usability (SUS), preference (7-point Likert scale), and interaction time (prompt to system response) [S1].
- Who/when: Google researchers; paper accepted at UIST 2025; blog dated Sept 18, 2025 [S1][S2].
- Sample and tasks: n = 10 participants completed 12 scenarios across six everyday activities using Android XR and WebXR in 360° videos or staged AR environments [S1].
- System under test: Sensible Agent uses a vision-language model for scene parsing, YAMNet to classify ambient audio events and noise, chain-of-thought prompting to select suggested actions and modalities, and multimodal inputs (gaze, head nods, hand gestures, or voice) to confirm [S1][S5][S6].
- Baseline: voice-controlled assistant modeled after Project Astra [S1][S7].
- Instruments: NASA-TLX (0-100 workload ratings) and SUS (0-100 usability scale) are standard in HCI evaluations [S3][S4].
- Key limitations: small sample (n = 10); mixed 360° and staged setups vs in-the-wild use; paper and blog report p-values but not standardized effect sizes; battery, latency budgets, and task success rates are not reported [S1][S2].
Findings: cognitive load, usability, and speed trade-offs in AR assistants
The study isolates how anticipatory suggestions and context-adapted modalities affect user burden compared with voice-initiated assistants. The data spans everyday contexts where speaking out loud or using hands may be inconvenient [S1].
Cognitive workload and effort
- Mental demand (NASA-TLX) averaged 21.1/100 for Sensible Agent vs 65.0/100 for the voice baseline (p < .001), indicating substantially lower perceived cognitive processing during tasks [S1][S3].
- Perceived effort also decreased significantly with Sensible Agent (p = .0039) [S1].
Interpretation: offloading query formulation - by proposing relevant actions as context signals appear - appears to reduce the mental steps required to use the assistant [S1][S2].
Usability, preference, and interaction time
- SUS: no statistically significant difference (p = .11), suggesting general usability was similar across both systems despite different interaction models [S1][S4].
- Preference: participants rated Sensible Agent higher (6.0 vs 3.8 on a 7-point Likert scale; p = .0074), citing less disruption and more natural, subtle exchanges such as nods [S1].
- Speed: time from prompt to final response was longer for Sensible Agent (28.5 s vs 16.4 s), an expected outcome of a two-step propose-confirm interaction [S1].
- Modality fit: Sensible Agent selected non-verbal confirmations when hands were occupied or environments were noisy (for example, gaze or head nod vs speech), which likely contributed to lower workload and higher preference despite longer sequences [S1][S5].
Interpretation and implications
- Likely: In consumer contexts where talking is awkward or ambient noise is high, assistants that propose timely actions and accept low-effort confirmations (gaze, nod, thumbs-up) reduce perceived workload and increase preference versus voice-only flows, even if total time increases [S1].
- Likely: Content and UX for AR should bias toward glanceable micro-prompts, binary or multi-choice confirmations, and non-verbal inputs when hands are busy or noise levels are high; optimize for mental effort and social comfort, not just speed [S1].
- Tentative: Campaigns or on-device experiences in retail, museums, transit, or kitchens may see higher acceptance and engagement when the system surfaces next-best actions contextually and limits speech dependence [S1].
- Tentative: Product metrics should include workload proxies (for example, short NASA-TLX items) and acceptance rate of suggested actions alongside task time; user preference data indicates people may trade speed for lower cognitive effort [S1][S3].
- Speculative: Combining longer-term user history with real-time signals (gaze, noise, hand state) could improve suggestion accuracy; on-device inference will be important for privacy and latency, especially for always-on AR [S1][S2].
Contradictions and gaps
- External validity: n = 10 and mixed 360° or staged setups limit generalization; no in-the-wild longitudinal data is reported [S1][S2].
- Missing outcomes: The study does not report task success or error rates, learning effects, or standardized effect sizes; energy and thermal budgets on XR hardware are not discussed [S1][S2].
- Usability detail: SUS differences were non-significant, but raw SUS means and confidence intervals are not provided, limiting comparisons to established SUS benchmarks [S1][S4].
- Equity and accessibility: No breakdown by demographics or accessibility needs; head or gaze gestures may not suit all users or cultural contexts [S1].
Sources
- [S1] Google Research Blog: "Sensible Agent: A framework for unobtrusive interaction with proactive AR agents," Sept 18, 2025.
- [S2] UIST 2025 paper: "Sensible Agent: A Framework for Unobtrusive Interaction with Proactive AR Agent." See UIST 2025.
- [S3] Hart, S. G., and Staveland, L. E. (1988). Development of NASA Task Load Index: Results of empirical and theoretical research.
- [S4] Brooke, J. (1996). System Usability Scale: A "quick and dirty" usability scale.
- [S5] Google AI/MediaPipe YAMNet: Audio event classification model.
- [S6] Wei, J. et al. (2022). Chain-of-thought prompting in large language models.
- [S7] DeepMind: Project Astra overview.






.svg)

.svg)
.svg)