
Google introduced Speech-to-Retrieval (S2R), a research approach to voice search that retrieves results directly from speech without first transcribing audio. Full technical details and evaluation are in the Google Research post Speech-to-Retrieval (S2R): A new approach to voice search.
Key details - Speech-to-Retrieval for voice search
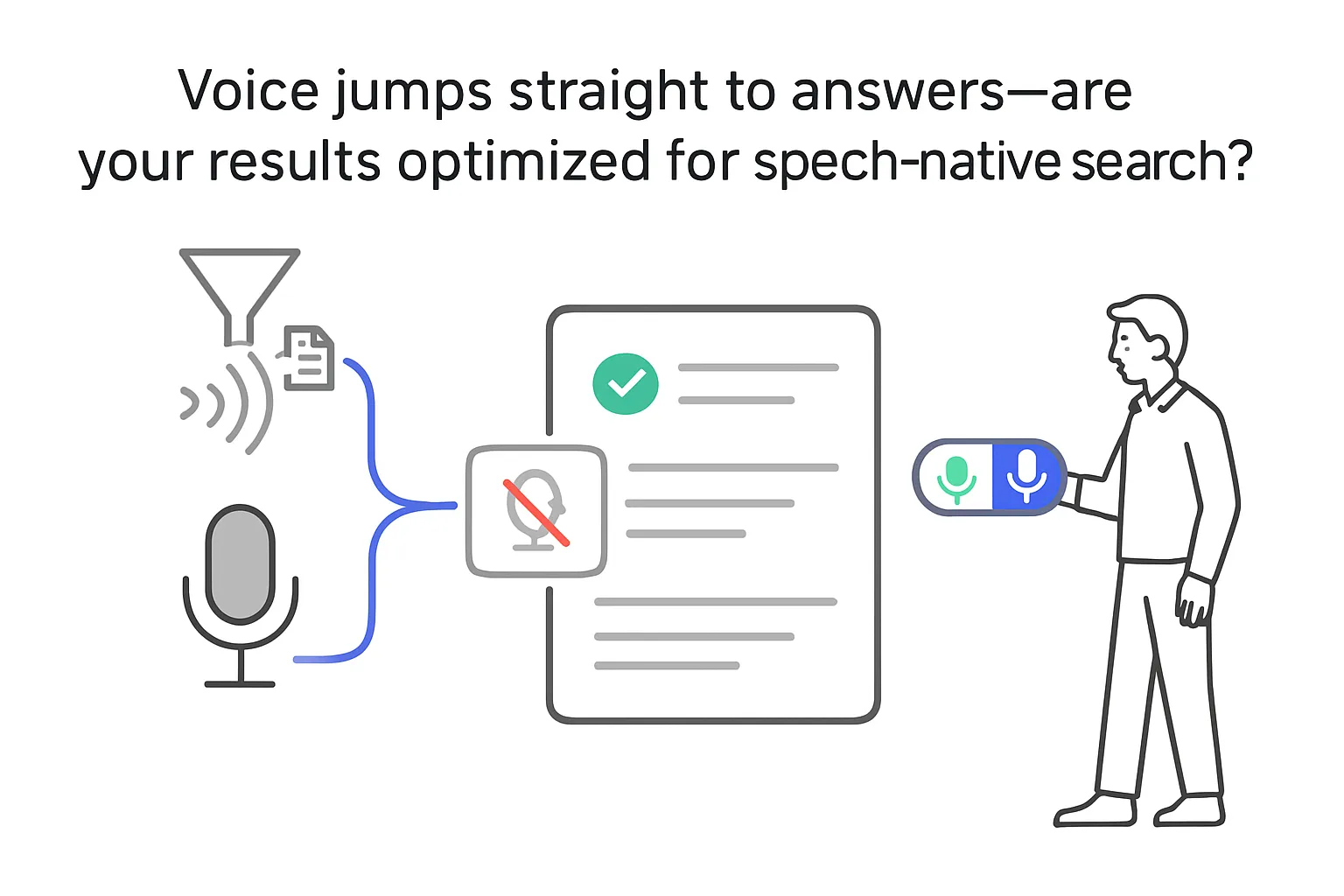
- S2R operates directly on spoken queries using a dual-encoder design - an audio encoder for speech and a text encoder for documents - trained jointly on paired data.
- The encoders map speech and text into a shared embedding space so related queries and documents are close together for retrieval.
- In internal tests, S2R outperformed a cascade automatic speech recognition baseline and approached a cascade system using ground truth transcripts.
- The blog covers model architecture, training setup, datasets, and retrieval benchmarks with task examples and comparisons.
- Official announcement: Speech-to-Retrieval (S2R): A new approach to voice search
Background
Traditional voice search pipelines transcribe audio to text with ASR, then run text retrieval. Errors in the transcription stage can propagate and reduce accuracy. S2R bypasses transcription by learning direct speech-to-document matching. It is trained on large sets of paired audio queries and relevant documents to align semantically related pairs, aiming to improve results for spoken queries with ambiguity or varied phrasing.






.svg)

.svg)
.svg)