
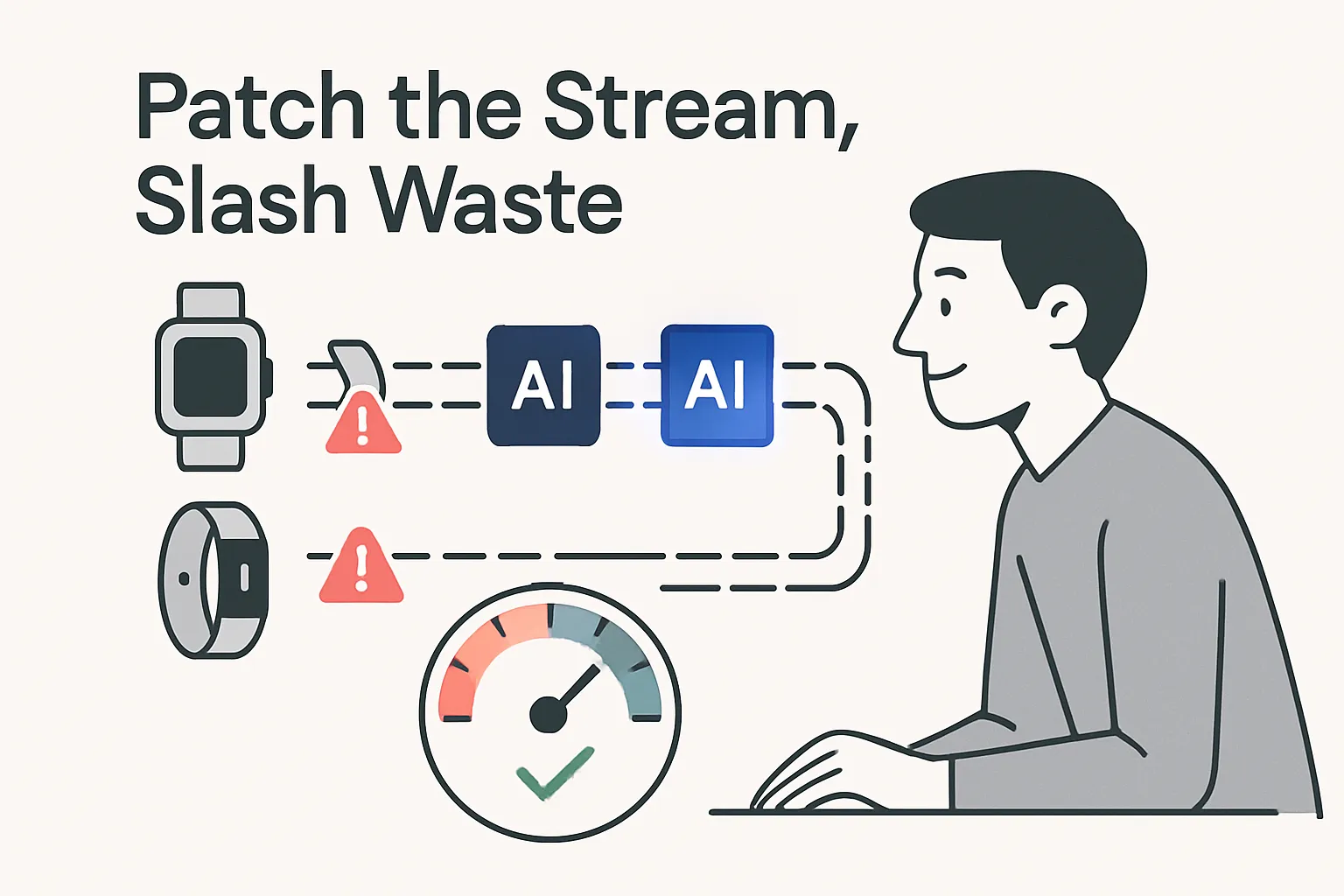
Wearable sensor data is growing faster than analytics teams can clean it, yet roughly 40% of the readings that reach a database are incomplete. Google’s new LSM-2 model claims to salvage much of that wastage by training directly on broken streams with an “Adaptive and Inherited Masking” (AIM) routine. If the approach works at scale, it could lower data-acquisition costs and reshape how health and fitness brands handle paid media, content, and product analytics.
Key Takeaways
- AIM accepts records with at least 50% missing values, shrinking usable-data loss from about 35% to 5-10% compared with clean-only pipelines. The result is broader audience panels for marketers.
- In benchmark tests, LSM-2 improved downstream task AUC by 0.03-0.06 and halved performance degradation during simulated sensor outages versus LSM-1, keeping targeting segments stable when devices misbehave.
- Google reports a 20% pre-training compute reduction thanks to token drop-out, producing similar savings in cloud budgets for in-house teams.
- Brands using Fitbit or Pixel data may see richer cohorts, for example night-shift workers who charge devices midday, and higher match rates in custom audiences.
- Because the model learns directly from missingness patterns, any hidden bias in those gaps is inherited - fresh fairness audits are mandatory before deployment.
Situation Snapshot
Event (22 Jul 2025) - Google Research published “LSM-2: Learning from Incomplete Wearable Sensor Data” alongside open benchmarks and code. The Paper covers 40 million hours from 60 000 participants; not a single sample had full coverage.
Facts - More than one billion parameters, trained on mixed Fitbit and Pixel streams. AIM pairs fixed token drop-out with an attention mask so the encoder never sees placeholder values. LSM-2 surpasses LSM-1 on classification, regression, and generative fill-in tasks under multiple missingness regimes.
Status - No commercial licensing has been announced.
How Adaptive and Inherited Masking Works
Most masked autoencoder frameworks hide a flat percentage of tokens to reduce compute, an assumption that fails for wearables where gaps spike unpredictably - for instance when a user charges a watch or the strap slips. AIM therefore splits the process:
- Token drop-out - Remove a fixed number of tokens up front, shortening the sequence and cutting floating-point operations by about 20%.
- Attention masking - Mask the remaining hidden or naturally missing positions so the encoder only attends to observed values.
During fine-tuning, only natural gaps exist, meaning attention masks handle 100% of missing points. Treating “missing” as a learnable feature instead of noise aligns with Self-supervised learning practice and avoids the synthetic bias that traditional imputation can introduce. Compared with heavy filtering, AIM keeps up to 30% more raw hours.
Google assessed embedding quality with a linear probe suite covering a wide variety of downstream health tasks, confirming that performance holds when sensors go dark.
Implications for Paid Media and SEO
For marketers, broader and cleaner embeddings translate directly into funnel improvements:
- Audience reach - Fewer discarded users extend look-alike lists in Google Ads by an estimated 10-15%. Larger lists often push CPMs down, but conversion quality needs monitoring.
- Attribution depth - Generative interpolation delivers continuous vitals, enabling brands to tie in-app triggers to overnight physiology events that were previously lost.
- Content strategy - Queries about “intermittent device data” or “battery gap analysis” will fade. Instead, low-competition clusters around “insight generation from partial data” emerge.
- Compliance and trust - Messaging must clarify that the model works on incomplete streams without guessing personal values, avoiding any perception of real-time medical advice.
Paid Search - Start with a 5% test budget; broader Smart Bidding signals should stabilise before scaling.
Organic - Publish technical explainers on self-supervised wearable AI to win early backlinks.
Creative - Highlight “works even if you take the watch off,” differentiating from rivals that still warn about data gaps.
Ops/Analytics - Nightly imputation jobs become optional, saving low five-figure USD per year for mid-size apps.
Operational Trade-Offs and Compliance
AIM removes one pre-processing stage but adds two governance tasks:
- Bias audit - Missingness can correlate with skin tone, occupation, or charging habits. Marketers should test for skew across cohorts.
- Consent scope - The training data was de-identified, but any commercial targeting requires a fresh privacy review.
On the technical side, GPU-level token masking is embedded in the model graph, making legacy ETL scripts obsolete. Migration will demand roughly one week of MLOps work plus one or two QA sprints.
Scenarios and Probabilities
- Base (60%) - Google folds LSM-2 into Fitbit Premium dashboards by Q4-25; no raw embedding API is released.
- Upside (30%) - A pay-per-call API opens and CPM for health-segmented audiences drops 10% thanks to inventory growth.
- Downside (10%) - Regulators label AIM’s handling of missingness opaque. The API launch stalls and gains revert to imputed pipelines.
Risks and Unknowns
- Exact accuracy deltas are drawn from paper graphs, not the full dataset.
- Missingness patterns vary across brands; results may not transfer to Apple Watch or Oura rings.
- EU AI Act deliberations could classify hypertensive-risk prediction as high risk, raising compliance overhead.
- If teams keep legacy imputation for other pipelines, the projected cost savings shrink.
Context and Prior Work
LSM-2 extends the lineage of wearable foundation models and follows the ICLR ’25 release of LSM-1 ICLR ‘25. Together they illustrate a broader trend: self-supervised methods are moving beyond language and vision into bio-signal territories where missing data is the rule, not the exception.





.svg)

.svg)
.svg)