
I put real time (and real money) into what I publish. Watching uninvited AI crawlers vacuum up pages for model training without a nod or a license does not sit right. The fastest lever I can pull is robots.txt. It is public, simple, and sets a clear policy that trims a lot of crawler noise. It is not a force field - some bots will ignore it - but it is a solid first wall while I wire up stricter enforcement at the edge.
Control AI bots with robots.txt
If I need a quick fix, I drop a focused A robots.txt file that blocks the major AI training crawlers and leaves search alone. It is a two-minute change if the site is already live.
Starter file that blocks GPTBot, Google-Extended, CCBot, PerplexityBot, and Applebot-Extended, while allowing everything else:
# Block common AI training crawlers
User-agent: GPTBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Applebot-Extended
Disallow: /
# Let everyone else crawl normally (e.g., search engines)
User-agent: *
Allow: /How I ship it fast
- Put the file at: https://mydomain.com/robots.txt
- Purge the CDN or edge cache so the new file actually serves
- Sanity-check it:
curl -A "GPTBot" https://mydomain.com/robots.txt
Why start here? Most large, reputable AI crawlers attempt to honor robots rules. It is easy to audit, easy to explain to stakeholders, and it buys me time while I add server-side filtering. Vendors like Google (Google-Extended) and Apple (Applebot-Extended) describe how their bots interpret robots - use those docs as your north star.
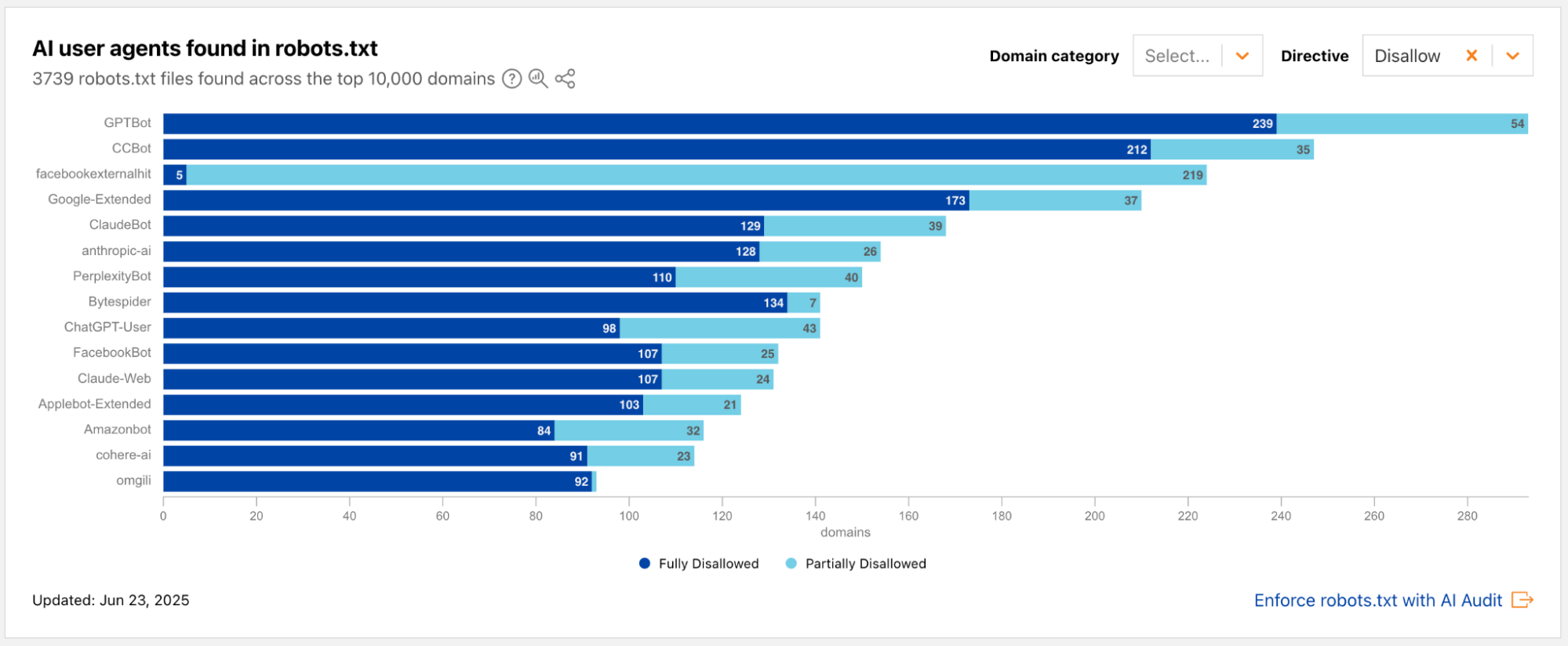
How AI crawlers read robots.txt (the bits that trip people)
- Longest matching path wins. The spec calls it the most specific match. In tie-breakers, Google’s implementation gives Allow precedence; not every bot guarantees that.
- User-agent matching is case-insensitive. GPTBot, gptbot, and GpTbOt all hit the same group.
- Paths are usually case-sensitive on the server.
/Docsand/docsare not the same. - Wildcards: Many major crawlers support
*and$(end anchor), but not all do. Test the patterns you rely on. - Order does not change logic; grouping by user agent just keeps the file tidy.
Selective access example
I keep public docs open and shut off sensitive or non-public surfaces:
User-agent: GPTBot
Allow: /docs/
Disallow: /pricing
Disallow: /proposals
Disallow: /members
Disallow: /api
Disallow: /staging
User-agent: *
Allow: /Is robots.txt important or merely advisory?
Both. It signals intent and reduces unwanted load, but it is not enforcement. That is why I pair it with server-side checks or WAF rules when I need guarantees.
Managed vs. self-hosted
- Managed: Some platforms let me edit robots.txt in a control panel or inject rules dynamically - great for fast, multi-site updates.
- Self-hosted in the repo: I get version history, code review, and repeatable local testing. Slightly more setup, much more control.
Complementary signals
- Add a Sitemap line so search engines keep indexing as intended. Example:
Sitemap: https://mydomain.com/sitemap.xml- see Sitemap basics. - Consider page-level intent signals like
X-Robots-Tag: noaior metanoimageai. They are not part of the classic search robots standard and will not control normal indexing unless I also usenoindex, but they clarify policy for AI training. - Sensitive content should never rely on robots alone - use auth or authorization.
OpenAI GPTBot: quick patterns
Block everything
User-agent: GPTBot
Disallow: /Allow-list a couple sections, block the rest
User-agent: GPTBot
Allow: /docs/
Allow: /blog/
Disallow: /Multi-bot partial allow
Open /docs/ and /press/, keep everything else closed to AI training crawlers:
User-agent: GPTBot
Allow: /docs/
Allow: /press/
Disallow: /
User-agent: Google-Extended
Allow: /docs/
Allow: /press/
Disallow: /
User-agent: CCBot
Allow: /docs/
Allow: /press/
Disallow: /
User-agent: PerplexityBot
Allow: /docs/
Allow: /press/
Disallow: /
User-agent: *
Allow: /Quick tests I actually run
- Fetch the file:
curl https://mydomain.com/robots.txt - Simulate GPTBot:
curl -A "GPTBot" https://mydomain.com/robots.txt - Confirm the exact directives are present and that your paths (including trailing slashes) match what is on the site.
GPTBot specifics and pattern tips
- Use the right token:
User-agent: GPTBot. Case does not matter for the token; path matching is case-sensitive. - When rules overlap, the longest path match wins. Many implementations let a specific Allow (like
/docs/) override a generalDisallow: /- see most specific match. - Trailing slashes signal intent.
Disallow: /members/makes it clear you mean the directory, not a file prefix. - File-type blocks are fine when needed:
Disallow: /*.pdf$ - Do not lean on
Crawl-delay. Many bots ignore it, and GPTBot does not guarantee respect for it. - Keep notes for yourself: where and why you allow a bot, plus any time limits.
Enforce policy at the edge (disallow scrapers that ignore rules)
User agents can be spoofed, so I combine UA filters with reverse DNS checks and, where offered, vendor IP verification.
Example CDN or WAF expression (blocks on high-risk paths even if some crawling is allowed elsewhere):
IF request.user_agent matches "(GPTBot|CCBot|PerplexityBot|Google-Extended|Applebot-Extended)"
AND request.path matches "^/(private|members|checkout|proposals|api)"
THEN BLOCK with 403Edge worker pseudo-code with reverse DNS confirmation:
export default async function handleRequest(req) {
const ua = req.headers.get("user-agent") || "";
const aiUA = /(GPTBot|CCBot|PerplexityBot|Google-Extended|Applebot-Extended)/i.test(ua);
if (!aiUA) return fetch(req);
// Extract source IP (platform-specific; adjust for your CDN)
const ip =
req.headers.get("cf-connecting-ip") ||
req.headers.get("x-forwarded-for") ||
req.conn?.remoteAddress;
// Pseudo helpers (implement with your runtime’s DNS APIs)
const rdnsHost = await reverseDns(ip); // e.g., crawler-xx.openai.com
const forwardIps = await forwardResolve(rdnsHost);
const forwardMatches = Array.isArray(forwardIps) && forwardIps.includes(ip);
const hostnameTrusted =
rdnsHost?.endsWith(".openai.com") ||
rdnsHost?.endsWith(".commoncrawl.org") ||
rdnsHost?.endsWith(".perplexity.ai") ||
rdnsHost?.endsWith(".googlebot.com") || // See vendor guidance for Google-Extended
rdnsHost?.endsWith(".applebot.apple.com");
if (!(forwardMatches && hostnameTrusted)) {
return new Response("Forbidden", { status: 403 });
}
// Optionally restrict only sensitive routes
const url = new URL(req.url);
const sensitive = /^\/(private|members|checkout|proposals|api)/.test(url.pathname);
if (sensitive) return new Response("Forbidden", { status: 403 });
return fetch(req);
}Some providers publish a Verified Bot list and even support cryptographically verifying their bot requests. Use those signals where available.
Protect ad-monetized pages without going nuclear
If ad revenue depends on human visits to certain routes, I only block AI crawlers there.
- Use predictable paths like
/ads/,/article/, or/sponsored/to identify inventory - Or tag responses (for example,
X-Ad-Inventory: true) and have the edge worker block AI UAs only when that header is present
Patterns like recognized ad units or Content Security Policy (CSP) reports can help identify pages that should get extra protection.
Add rate limiting for abuse
If a bot pounds endpoints faster than polite crawl rates, I throttle or block by IP or range. Combined with robots policy, this keeps resource drain low while preserving UX.
Verify GPTBot (and friends) before trusting them
I separate real crawlers from impostors using reverse DNS plus vendor documentation.
My validation steps
- Grab the source IP from logs or CDN headers.
- Reverse lookup that IP to get a hostname.
- Forward-confirm the hostname and ensure the original IP is in the returned set.
- Check the hostname suffix against the vendor’s documented domains.
Handy CLI
- Reverse lookup an IP:
dig +short -x 20.15.240.80 - Forward-confirm a hostname:
dig +short crawler.example.openai.com - Alternate:
host 20.15.240.80andhost crawler.example.openai.com
Red flags I watch for
- RDNS does not forward-confirm to the same IP
- Hostname suffix does not match the vendor’s documented domains
- Mixed or malformed user agents
- Crawl rates that spike or look erratic compared to normal bot behavior
If something looks off, I block first, then investigate, and (if needed) notify the vendor. Clear notes on my side make follow-ups painless.
A practical robots.txt playbook for AI
- Default-deny sensitive areas like
/proposals,/members,/checkout, and/api. Allow-list what must be public (for example,/docs,/press). - Keep AI training controls separate from search crawling so marketing and SEO do not take collateral damage.
- Version-control robots.txt and add a CI check that fails the build if key directives vanish.
- Put the policy in my Terms. State that model training, dataset creation, and redistribution require a license.
- Monitor and iterate. New bot tokens appear regularly - update rules when they do, and flip your GPTBot stance if policy changes.
- Test staging and production separately; staging typically disallows everything.
- Do not block assets used by search rendering. Disallowing critical JS or CSS can tank SEO rendering. See how large sites do it in https://www.google.com/robots.txt.
Common footguns
- Robots is advisory. Pair it with WAF or edge rules for anything sensitive.
- Path case matters:
/Pricingand/pricingare different. - Trailing slashes are not cosmetic. Be explicit when you mean a directory.
- Wildcards help, but always test against real URLs with
curl.
Manage LLM crawler access at scale
If I am running multiple sites, I turn policy into a tiny utility so updates are consistent.
One workable setup
- Keep a central policy file (for example,
ai.robots.policy.json) listing AI user agents and desired path rules. - Use a small generator to emit robots.txt per domain based on environment. Production might allow
/docs/and/press/; staging blocks all. - Schedule updates: publish, purge caches, and alert the team when changes go live.
Want a turnkey example generated at build time? See this tiny script: build.js, or try it in minutes: Deploy to Netlify.
Example policy file
{
"bots": [
"GPTBot",
"Google-Extended",
"CCBot",
"PerplexityBot",
"Applebot-Extended"
],
"rules": {
"production": {
"allow": ["/docs/", "/press/"],
"disallow": ["/", "/pricing", "/proposals", "/members", "/api"]
},
"staging": {
"allow": [],
"disallow": ["/"]
}
}
}Tiny generator concept
function buildRobots(env, policy) {
const { bots } = policy;
const allow = policy.rules[env].allow || [];
const disallow = policy.rules[env].disallow || ["/"];
let text = "";
for (const bot of bots) {
text += `User-agent: ${bot}\n`;
for (const p of allow) text += `Allow: ${p}\n`;
for (const p of disallow) text += `Disallow: ${p}\n`;
text += "\n";
}
text += "User-agent: *\nAllow: /\n";
return text;
}Governance beats clever code
- One team owns the policy - no mystery edits.
- Review monthly and after any incident.
- Alert on unexpected AI bot hits (for example, notify when GPTBot requests a blocked route).
- Keep a lightweight exception process. If a partner needs temporary access, log it, time-box it, and set a reminder to remove it.
Useful references
- A robots.txt file - what it is and how it instructs crawlers.
- RFC 9309 and the most specific match rule.
- Google-Extended - keep Googlebot for SEO while opting out of AI use.
- Applebot-Extended - how to opt out of Apple’s AI training.
- Blockin’ bots and Blockin’ bots on Netlify - background and implementation details.
- Example from a large site: https://www.google.com/robots.txt
- More fundamentals: robots.txt
With this in place, I control AI access at the policy layer and back it up at the edge. The result is calm and measurable: protect IP, keep search visibility, and avoid busywork.



.svg)

.svg)
.svg)