
If you run a B2B services company, you probably feel the daily pinch: too many files, not enough time, and search results that hide the asset you need. Automated tagging solves that bottleneck by turning messy folders into findable, compliant libraries that anyone on your team can trust. I cut guesswork, drive reuse, and move campaigns faster when metadata writes itself and humans focus on exceptions. New to the space? Start with a primer on What is DAM.
What automated tagging in digital asset management really is
Automated tagging in digital asset management (DAM) uses AI to scan images, videos, audio, and documents, then generate metadata - objects, scenes, people (where allowed), text, topics, and rights cues. The payoff shows up in hours saved, sharper search results, and stronger compliance coverage across brand, rights, and privacy.
Manual tagging asks people to label every file, which drains time and creates gaps. I keep people in control but let the machine handle the repeatable work. Assets that fall below a confidence threshold route to a quick human review; everything else flows through. The result: quality stays high, and skilled time shifts from labeling to creative and strategy.
ROI and business impact you can quantify
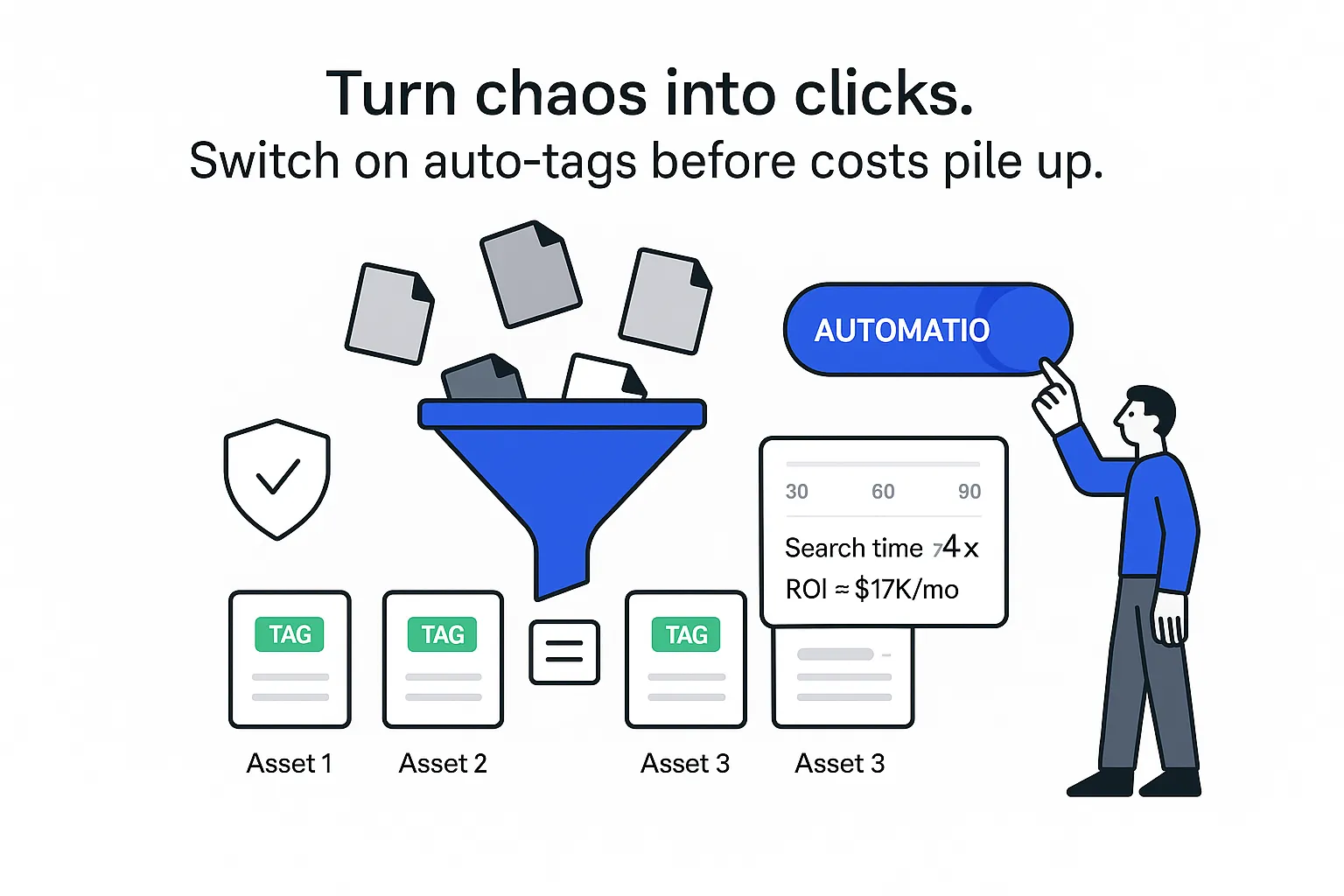
Time is the first win. Manual tagging commonly takes two to five minutes per asset. At 5,000 assets per quarter, that is 10,000 to 25,000 minutes of skilled work. AI reduces this to seconds per file and moves reviewers to an exceptions list. Search quality and Search & Discovery improve because precise tags surface the right asset fast, and Workflows & Automations cut handoffs.
A practical example
- Time saved per asset: 3 minutes
- Assets per month: 2,000
- Loaded cost per hour: 70 dollars
- Hours saved: 2,000 × 3 ÷ 60 = 100 hours
- Monthly savings: 100 × 70 dollars = 7,000 dollars
- Add reuse uplift: even a 10 percent bump in reuse at a 50 dollar average re-creation cost adds 2,000 × 10 percent × 50 dollars = 10,000 dollars
- Estimated monthly value: 17,000 dollars before counting faster launches
Search and campaign velocity improve together:
- Time to find drops from minutes to seconds
- Reuse rises because assets surface with precise tags
- Approvals start sooner, so campaigns ship earlier
Case snapshot
In one anonymized B2B consulting firm with 60 sellers and 120,000 assets spanning brand, case studies, and training videos, the median search time fell from 4 minutes to 45 seconds after 90 days. Reuse rose from 22 percent to 37 percent, and rights exceptions dropped by roughly 70 percent. Pipeline content reached the field about a week earlier on average.
If you want a quick formula, think: monthly value equals (assets × minutes saved × hourly cost ÷ 60) plus (assets × reuse uplift percent × re-creation cost). I treat this as a directional estimate and validate it against actual search logs and production metrics.
A DAM workflow that scales without chaos
I keep the lifecycle simple and governed:
- Ingest: Batch upload from creative tools, PIM/CRM, and cloud drives. Preserve embedded metadata on the way in. See how to Ingest metadata at scale.
- Auto-tag: AI extracts objects, text (OCR), scenes, logos, and people where policy allows. Store confidence scores with each tag.
- Human-in-the-loop QA: Anything below the threshold goes to an exceptions queue. High-value assets can always route to review.
- Approvals: Roles and permissions define who can approve metadata, rights flags, and publish status. Administrators can limit who creates or edits terms.
- Distribution: Publish to portals, CMS, sales enablement, and campaign folders. Connectors and Integrations keep downstream channels in sync. Audit logs track who did what and when.
I set confidence thresholds by asset type. For example: 90 percent for product shots, 80 percent for event photos, 95 percent for anything with sensitive content. I keep queues short and track the auto-approve rate - how many assets pass without review. That metric reveals the real time saved.
To prevent noisy tag clouds, I cap auto-tags per asset and keep only the highest-confidence items. If more than 25 tags appear by default, I trim aggressively.
What today’s models can (and can’t) do
Modern models cover a lot of ground:
- Object and scene detection: people, laptops, offices, lab equipment, whiteboards
- Logo detection: spot brand marks across your company and partners
- OCR: pull text from slides, screenshots, and scanned PDFs
- PII redaction: blur faces, license plates, and emails where policy demands
- Video scene detection: segment long videos into labeled scenes with timestamps
- Speech-to-text: generate transcripts for audio and video
How I choose and measure
- I start with a broad, general model for coverage, then add a small domain model for business-specific tags (niche equipment, service lines, internal product names). See the AI feature set here: AI.
- I measure quality with precision and recall, and combine them as F1 to track overall accuracy. False positives are the enemy of trust, so I watch them closely and tune thresholds to avoid over-tagging.
- I monitor drift. Models learn from data; if my library over-represents a setting or style, bias can creep in. I counter it with diverse training samples and targeted human review for high-stakes assets.
Guardrails that keep results usable
- Cap low-value tags and promote only high-confidence terms into the approved vocabulary.
- For sensitive content, require review before publish and keep an auditable trail of overrides.
- Re-evaluate thresholds quarterly as asset mix and model quality change.
Taxonomy plus enrichment: where accuracy becomes findability
Auto-tags are a start. The real power appears when those tags map to a controlled vocabulary my teams recognize. For fundamentals, see the DAM Glossary. Better taxonomy directly improves Search & Discovery.
How I map and govern
- Raw tags like laptop or whiteboard map to approved terms like Device and Collaboration Surface.
- Synonyms keep search consistent, so notebook resolves to laptop automatically.
- I use singular labels, consistent case, and avoid abbreviations unless they are standard.
- Relationships matter: broader/narrower links (SKOS style) make navigation intuitive.
- I review new tags weekly early on, shifting to monthly once patterns stabilize, and I limit who can add or edit terms with version history for audits.
Enrichment adds business context
- Embedded data (EXIF, IPTC, XMP, DICOM where relevant) travels with the file.
- Business systems supply product names, client segments, and campaign codes.
- NLP contributes keywords from transcripts, summaries for long videos, and chapter markers.
- Rights and usage data - license terms, expirations, region limits, and credit lines - ensure safe reuse.
Rules stitch it together:
- If brand equals X, apply license Y and region Z
- If asset type equals case study, add funnel stage equals Consideration
- If creator is external, require credit and contract ID before publish
A quick before/after
- Before: Title: Q2 webinar hero; Tags: people, laptop, meeting
- After: Title: Q2 webinar hero; Tags: Thought Leadership, Device equals Laptop, Collaboration Surface equals Whiteboard; Business: Campaign code equals Q2WL, Segment equals Mid Market; Rights: License equals Getty 12345, Expires equals 2026-06-30, Region equals North America; Transcript keywords: onboarding, ROI, integration time
Implementation in 90 days without a bloated plan
I prefer a focused rollout that shows results fast.
Phase 1 (days 1-30)
- Pick two asset types and one team
- Test two AI providers on the same labeled set
- Set thresholds, define exceptions rules, and map raw tags to a small taxonomy slice
- Train reviewers on the QA queue
- Milestone: 80 percent of pilot assets tagged with under 10 percent manual edits
Phase 2 (days 31-60)
- Add asset types and one distribution channel
- Connect CRM/PIM fields that drive real search needs
- Publish a short naming and tagging guide
- Milestone: median search time under 60 seconds for pilot users
Phase 3 (days 61-90)
- Roll out roles and permissions broadly
- Turn on audit logs and weekly accuracy reports
- Tune thresholds based on exceptions volume
- Milestone: 70 percent reduction in tagging time from baseline
Migration and risk controls I do not skip
- Inventory libraries, remove obvious duplicates, and preserve embedded metadata during ingest
- Import taxonomy terms and synonyms, and map old fields to new ones with a field dictionary
- Validate a random sample post-import for accuracy
- Keep a rollback plan for bulk updates, run daily audit logs for tag changes, and use a staging environment for rule edits
- Assign clear owners for taxonomy, AI settings, and QA
Pitfalls I watch for and patterns that keep adoption high
Common traps
- Messy taxonomy: near-duplicates, unclear labels, no rules
- Noisy tags: generous models flood assets with low-value labels
- Low adoption: users search with their own terms and miss assets - or stop trusting results
- Compliance drift: rights fields, expirations, or policy checks get skipped
What works in practice
- Human QA on high-value assets: I define a short list by asset type or campaign importance
- Feedback loop: a simple correction workflow routes fixes to model or taxonomy owners
- Search analytics: I review zero-result searches and common queries, then add synonyms or new terms
- Governance rhythm: a small committee meets monthly to approve changes and publish short release notes
- Privacy checks: enable PII detection for images and transcripts, and require approval for anything flagged
- Adoption nudges: autocomplete with approved labels and synonyms, saved searches for common asks, and short how-to clips for approving tags or fixing a miss
Accuracy matters, but trust matters more. When users see consistent labels, fast search, and clear rights data, they come back. When leaders see time saved and fewer mistakes, they lean in. Automated tagging in digital asset management becomes part of how I work, not another system to babysit.
Start narrow, measure, then expand. I keep humans in the loop where it counts and let the machine carry the rest. The teams I support get back hours, the library gets easier to search, and campaigns stop waiting on metadata.



.svg)

.svg)
.svg)