
AI is finally moving from lab demos to real work. That is great for growth and risky for brand and compliance if it is left unchecked. I use LLM guardrails to cut incidents, speed up approvals, and keep production teams sane without micromanaging every thread. The goal is not to smother the model; it is to keep it within policy while preserving speed, accuracy, and context. For examples of where LLMs are landing today, see more real-world applications.
Why I care about LLM guardrails now
LLM guardrails are the controls that keep model behavior on track in production. I think of them as policy-aware filters and validators wrapped around the model, catching unsafe prompts, enforcing formats, and blocking risky outputs before they reach customers or systems. I lean on them now because teams want faster time-to-production with fewer fire drills, cleaner audits, and confidence that AI will not say or do something that causes legal exposure, brand damage, or system failures.
Deployed well, guardrails reduce incident volume, shrink legal risk, and make compliance reviews smoother. They shorten the path from prototype to production without suffocating performance. I prioritize a small, high-impact set of controls early, then expand coverage based on real telemetry and business risk. If you are integrating models with external systems, strong routing and validation help maintain output reliability and control and simplify integration with APIs.
What I mean by guardrails (layers and purpose)
Guardrails are control points that guide and limit what the system accepts, how it reasons, and what it emits. I apply them at three layers, each addressing a different class of risk:
- Pre-prompt guardrails: clean and constrain inputs. Examples include regex filters for PII, injection-prevention classifiers, parameterized templates, and tool whitelists that prevent the model from seeing raw user text or calling unapproved functions.
- In-model guardrails: shape the reasoning path. I use structured prompting, tool-use limits, and constrained decoding to keep outputs within valid sets and budgets.
- Post-generation guardrails: validate content before it reaches users or downstream systems. This includes retrieval-backed factuality checks, policy enforcement, and strict schema validation.
For B2B scenarios, this lets me lock down common failure modes:
- Customer support: cap refunds, route legal topics, block unsafe instructions, and require citations to internal docs.
- Proposals and SOWs: enforce pricing tables and approved terms, ban speculative claims, and reference current contract language.
- Data analysis: keep SQL read-only unless approved, restrict datasets, and require justification on flagged anomalies.
I track risk categories explicitly: brand safety, legal exposure, data loss, fraud, financial out-of-policy actions, and technical format issues that break downstream systems.

The outcomes I target (and what to measure)
I set targets that are aggressive but realistic. Actual results vary by domain, data quality, model choice, and baseline process maturity. Treat these as directional, not guarantees, and tie them to business KPIs and compliance frameworks (for example, OWASP Top 10 for LLM Applications, NIST AI RMF, ISO 27001, SOC 2).
- In 30 days: reduce prompt-injection incidents by roughly 40-60% with input filters, instruction hardening, and tool whitelisting.
- In 60 days: reduce hallucinations in customer-facing flows by about 30-50% using retrieval checks and schema validation. See practical tactics for hallucination reduction and evaluation via LLM-as-a-judge and Faithfulness metrics.
- In 90 days: reach meaningful SOC 2 and ISO 27001 control coverage with audit trails, role-based access, and policy libraries tied to GDPR/CCPA/HIPAA/PCI where relevant.
- Latency overhead: keep added guardrail latency under ~50 ms per request by using lightweight classifiers and caching common checks; set end-to-end SLOs (for example, P50 < 800 ms, P95 < 1,800 ms) for the full trip including guardrails.
- Sensitive data: drop PII exposure risk by up to ~80% with input/output detection, masking, and memory constraints.
- Customer experience: improve CSAT on AI-assisted support by ~5-10 points after adding confidence scoring and human escalation rules.
- Cost predictability: achieve stable cost per conversation by enforcing tool-use ceilings, token budgets, and autoscaling limits with alerts and hard stops.
For executives, the fastest wins come from three moves: a standard policy pack, an LLM evaluation framework with real KPIs, and runtime monitoring that surfaces issues before customers do. For background on designing resilient pipelines, see output reliability and control.
How I evaluate safety, offline and online
Evaluation is where good intentions turn into measurable safety. I use both offline and online evaluation, grounded in business outcomes, not just model scores. Start with reliable ground truth and expand with automated methods like LLM-as-a-judge.
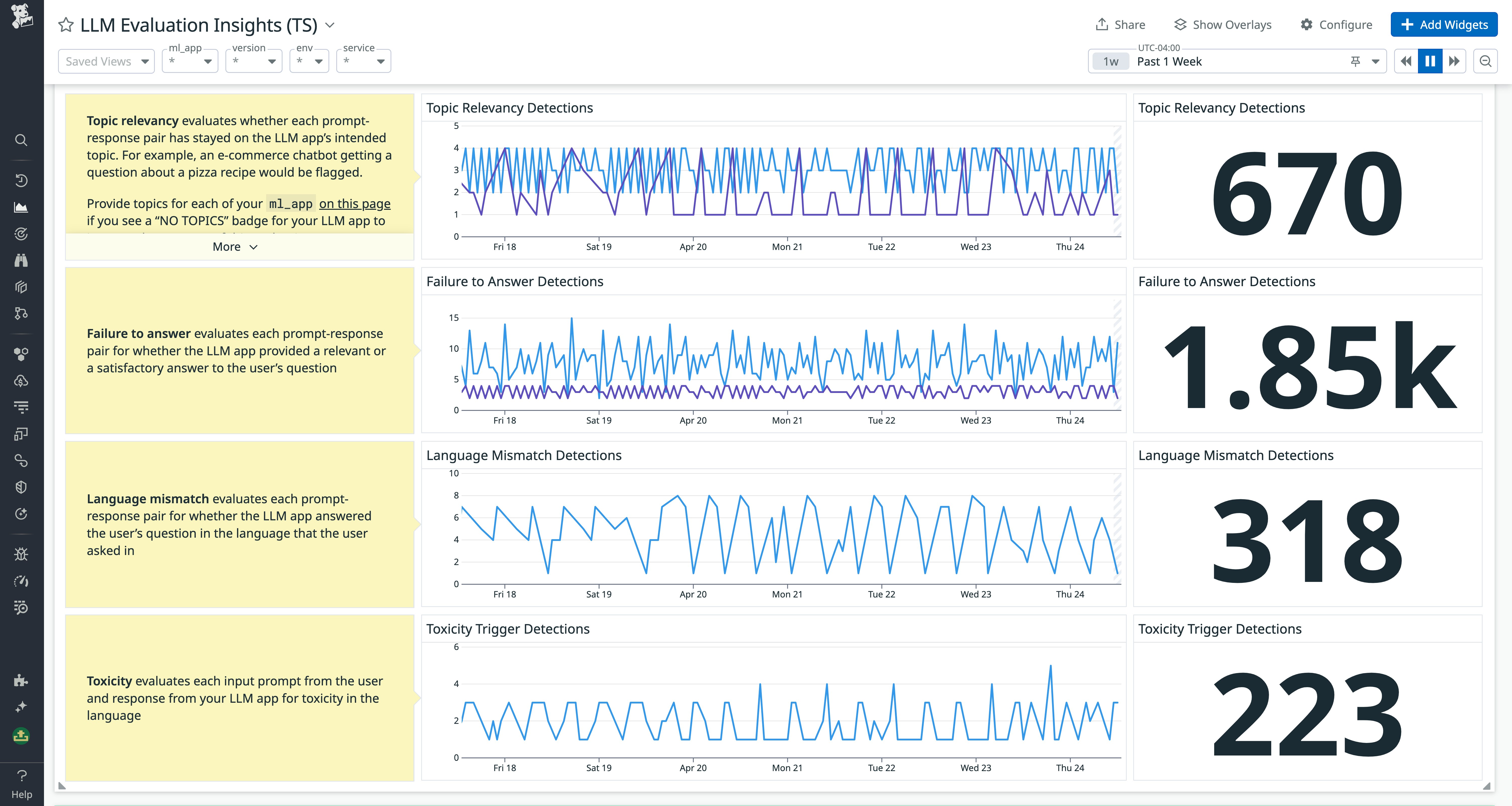
Offline evaluation
- Golden sets: curated prompts and expected outputs for core tasks, including tricky edge cases. I refresh these monthly.
- Adversarial test suites: prompts designed to break rules, trigger jailbreaks, or confuse tool selection. I pull from OWASP guidance and past incidents, plus research on jailbreaking and tools like JailbreakEval.
- Rubric-based scoring: a clear 1-5 scale for faithfulness, safety, tone, format, and actionability, with unambiguous rubrics. Useful implementations include Ragas and DeepEval.
- Human-in-the-loop: expert review on 5-10% of high-risk flows; I capture comments, not just scores. Background on human-in-the-loop.
Online evaluation
- Shadow mode: run models behind the scenes and score results before routing live traffic.
- Canary buckets: send 1-5% of traffic with guardrails; compare against a control cohort.
- SLA checks: monitor latency, timeouts, error rates, and tool failures; alert on violation trends. Telemetry is best obtained via traces.
- Guardrail hit rates: track how often each rule fires by channel and tenant to spot drift or overblocking. Watch for model drift.
I map results to KPIs by function:
- Customer support: escalations per 1,000 tickets, first-contact resolution, handle time, CSAT.
- Sales assist: qualified meetings per week, reply quality score, quote accuracy.
- Compliance: audit findings, rule violations by category, time to remediation.
- Cost: tokens per task, tool calls per task, cost per solved case.
A compact scorecard keeps everyone aligned:
- Faithfulness: percent of claims backed by retrieved facts, grounded in Faithfulness research.
- Safety: zero-tolerance categories, thresholded categories, and allowed categories with notes.
- Latency: P50/P95 guarded roundtrip targets.
- Cost: budget per request, with alerts at 80% and hard stops at 100%.
- Format: JSON schema compliance, markdown sanitation, forbidden-content checks.
- Security: PII detection events, secrets exposure attempts, and tool-call scope violations.
I put review cadences on the calendar - weekly for high-traffic flows, monthly for others - and I keep decision logs. If I loosen a guardrail to speed a workflow, I record why and define explicit rollback triggers.
From prototype to production without surprises
I move in stages that risk and compliance teams recognize:
- Sandbox: fast iteration with a narrow policy pack and read-only data. I add input sanitization, prompt hardening, and tool whitelists.
- Gated beta: small internal or friendly-user cohort. I enable JSON schema enforcement, PII detection, content moderation, and confidence thresholds.
- Canary: 1-5% of traffic. I turn on runtime monitoring, incident routing, and kill switches; I compare results to a control.
- General availability: full rollout with change approvals, version pins, and rollback plans.
Minimal production controls I consider table stakes:
- Rate limits and concurrency caps per key.
- Input and output filters for PII, secrets, and forbidden topics.
- Secrets vaulting for API keys and tool credentials - never in prompts or logs.
- Verdict logging for every guardrail decision, with trace IDs and model versions.
- Canary flags and instant kill switches by feature, tenant, and geography.
- Versioning with approval gates and auto-rollback when KPI thresholds are breached.
- RACI clarity: who owns policies, who approves changes, who gets paged.
- Audit trails across prompts, retrieved context, tool calls, and final outputs.
Change management needs to be boring and reliable. I tie every model or prompt update to a ticket, a test run, a canary plan, and explicit rollback conditions. If a risk owner cannot see these parts in one place, it is not ready for production.
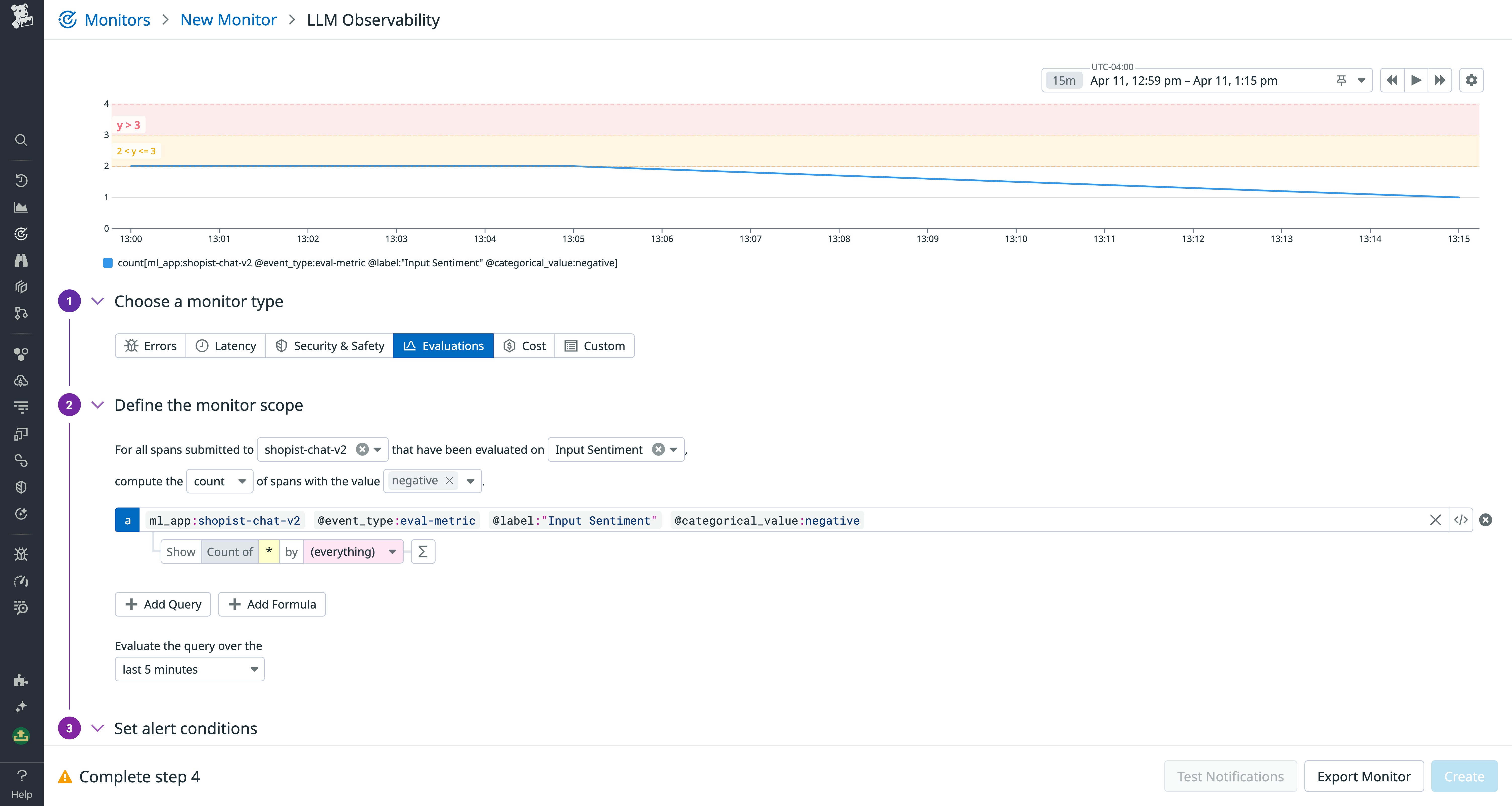
What to implement and where it runs
I mix simple filters with smarter models and keep latency within budget. Different methods cover different risks.
Core guardrail categories and when I favor them
- Prompt injection prevention: instruction hardening, jailbreak classifiers, and tool-call isolation for any external input or third-party data. Tradeoff: higher precision lowers false positives but may miss clever attacks. Refresh adversarial prompts often and monitor with this blog post.
- Hallucination mitigation: retrieval checks that compare claims against sources, validators that require citations or confidence scores. Tradeoff: added latency; cache frequent answers and pre-compute embeddings. See Retrieval-Augmented Generation (RAG) pipeline and the classic needle-in-the-haystack test with context like Google Gemini.
- PII detection: scan inputs and outputs for names, addresses, account numbers, and more; mask or hash automatically; watch for data drift such as new identifiers.
- Policy enforcement: map business rules to machine-readable checks such as refund caps, identity verification, escalation paths, and style rules. Tie to ISO 27001, SOC 2, HIPAA, PCI, GDPR, and CCPA where applicable.
- Content moderation: filter profanity, hate, threats, and self-harm with graduated responses from soft warnings to hard blocks. For definitions and models, see “abusive speech targeting specific group characteristics, such as ethnic origin, religion, gender, or sexual orientation.”, this one from Meta, and options for Negative sentiment evaluations.
- Tool-use constraints: whitelist functions, set argument ranges, cap frequency, and require approvals for write actions or financial steps. For more complex flows, see multi-step or agentic systems.
- Rate and abuse limits: cap requests per minute, token budgets, and prompt length to prevent prompt storms and cost spikes.
Implementation tactics I rely on
- Regex/pattern filters: fast, cheap, auditable for credit cards, SSNs, and forbidden phrases.
- Classifiers and safety models: detect jailbreaks and unsafe content; choose small models for speed and larger ones for gray areas.
- Retrieval augmentation: back answers with trusted documents; if no source is found, return a safe fallback rather than free-form speculation.
- Constrained decoding and strict JSON schema validation: force outputs into formats systems expect; reject or repair on failures. Examples of programmatic guardrails.
- Function whitelists: bind the model to approved tools and narrow parameter ranges. Prompting patterns like Anthropic Claude tips and self-critique reflection can help.
- Red teaming: scheduled attack prompts for prompt leakage, content laundering, tool misuse, and social engineering.
- Runtime monitoring: track guardrail hits, false positives, timeouts, and cost per request; alert on spikes and drift.
Where I integrate guardrails
- API gateway: rate limits, auth, geo rules.
- Middleware: input sanitization, policy checks, and PII masking before prompts are built.
- Vector database: retrieval sources and citation checks with a robust RAG pipeline.
- Secrets manager: key rotation and leakage prevention in prompts and logs.
- SIEM and ticketing: push incidents, track remediation, and close the loop.
I encode SLO-aligned rules in config, for example:
- If JSON schema fails twice, escalate to a human and stop the flow.
- If confidence < 0.6 on a high-risk category, return a knowledge base link instead of free text.
- If cost per request exceeds budget, reduce context length and suppress low-value tools.
A useful reference for consistent templates is these templates. When evaluating agents and chains, consider telemetry-first designs with obtained via traces.
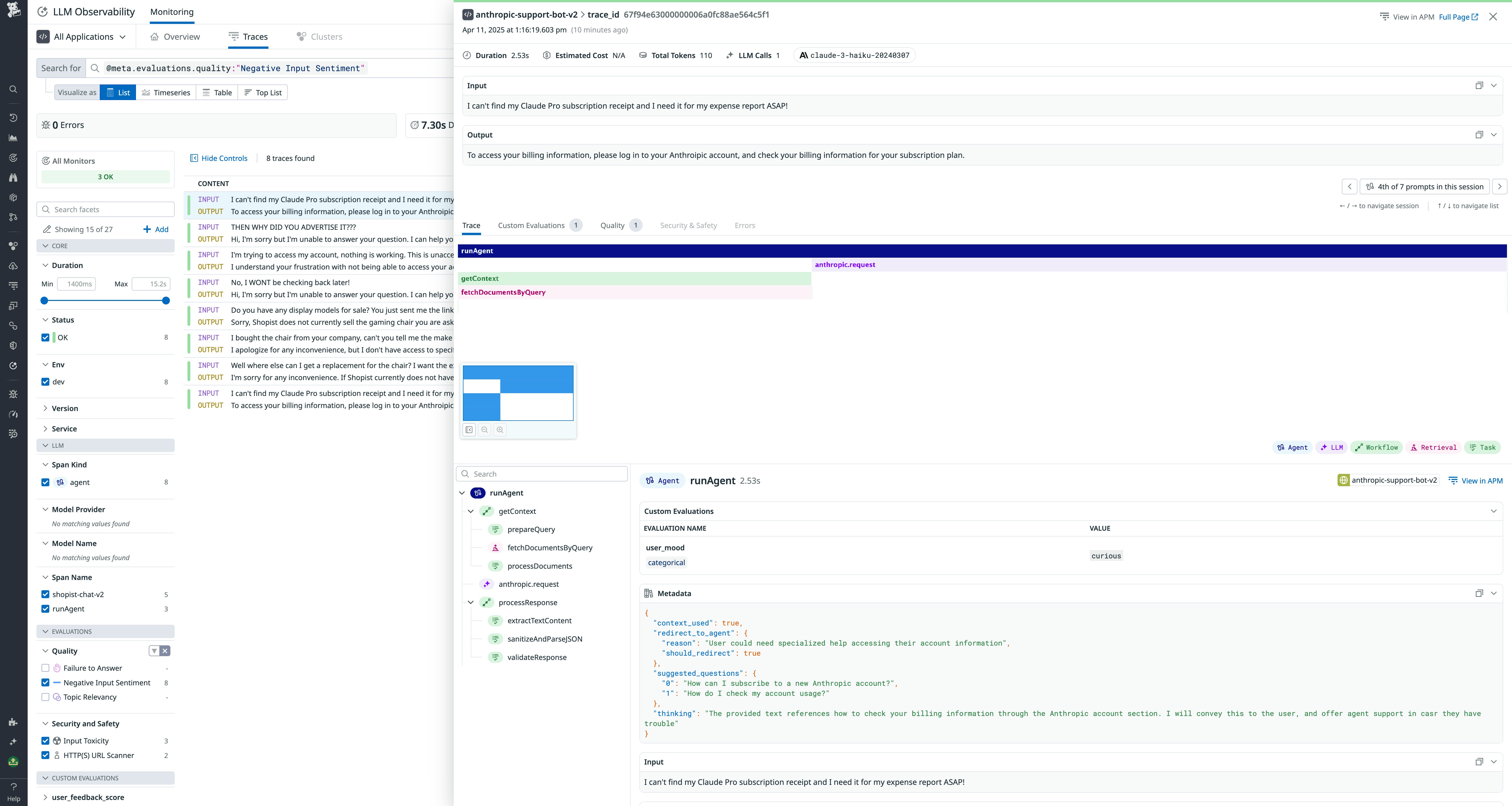
A typical guarded request pipeline I use
- Sanitize input.
- Detect and mask PII.
- Detect and block injection attempts.
- Retrieve trusted context.
- Generate a draft with a structured prompt.
- Validate schema; repair or block on failure.
- Run safety and policy checks; block or redact on failure.
- Check factuality against retrieved context; fallback if unsupported.
- Log verdicts with trace IDs and versions.
- Return the approved output.
For long-context performance and recall, tests like the needle-in-the-haystack test and vendor writeups such as Google Gemini are useful. Also consider agentic evaluation for multi-step or agentic systems.
Observability and continuous improvement
If I am selecting a platform or stitching a stack, I look for real control with clear data, not black boxes. Baseline criteria:
- Breadth of policies: built-in rules for PII detection, content moderation, tool-use limits, and financial actions.
- Explainability: reason codes and remediation guidance for each block or pass.
- Latency impact: production-grade checks with small overhead and caching options.
- Multi-model support: switch providers and sizes without rewriting guardrails.
- Auditability: immutable logs with trace IDs, model versions, prompts, retrieved context, and verdicts. See the official documentation.
- Certifications and controls: SOC 2, ISO 27001, data residency options, configurable retention.
- Role-based access: separation of duties for admins, developers, reviewers, and auditors.
- Analytics: guardrail hit rates, false-positive analysis, cost per request, per-tenant views.
- Incident workflows: routing, severity tags, playbooks, time-to-resolution tracking.
- Migration path: import existing rules, prompts, and golden sets.
Two composite scenarios that illustrate measurable impact:
- Support automation handling ~15,000 tickets per week adds PII detection, citation checks, and refund caps. Within eight weeks, escalations drop by about one-third, and legal review requests fall because answers cite trusted docs by default.
- Proposal generation with price tables and legal terms adds schema checks, policy enforcement for discount limits, and human review on high-value quotes. Error-prone drafts shrink, approvals speed up by roughly a day, and finance sees fewer off-policy quotes.
To keep trust high after launch, I layer AI observability across the pipeline and watch business signals alongside model metrics. I tie alerts to SLOs, run quarterly red teaming with updated attack suites, document changes, and keep approvals crisp. Most importantly, I treat guardrails like product features: give them owners, budgets, and goals; publish results - good and bad; and tie them to revenue and risk. For broader platform context and tooling, see infrastructure and LLM ops powered by traces. If you need a place to start operationalizing this, Try Orq.ai free.



.svg)

.svg)
.svg)