
I want reach, in many languages, without the long, expensive slog. That is what modern speech AI delivers when I set it up with intent. The workflow below moves from raw video to publish-ready voiceover, with practical notes to help a CEO or CTO decide where speed wins, where quality matters, and how to balance both. Done well, I have seen teams cut dubbing turnaround by 40-60 percent without measurable loss in listener-rated naturalness (e.g., MOS on sampled clips). Validate that claim in your own context with a small pilot, not a hunch.
Multilingual voice cloning
If my goal is faster time-to-value, multilingual voice cloning lets me turn one strong piece of audio or video into many, while preserving brand voice and tone. Think training modules, sales demos, or founder videos that still sound like the original speaker in Spanish, French, or Japanese. The quality bar for human-like speech is now high enough that viewers stay engaged while production overhead falls.
The key trade-off is speed versus stability:
- Zero-shot systems can clone a voice from a brief sample and spin up many languages quickly. Great for pilots, internal content, and short clips.
- Few-shot cloning needs several curated samples and a bit more setup but sounds steadier on long recordings and tricky names.
In practice, I mix both: zero-shot for lower-stakes assets, few-shot for marquee content or long monologues. I still plan a full workflow, not a single click: clean audio, accurate transcripts and translations, and natural text-to-speech with proper timing. I automate the pipeline so human effort concentrates on review, not grunt work.
Video file preparation
Input quality still determines output quality. Better prep yields better ASR, better translation, and fewer retakes. I check these parameters before transcription:
- Container and codecs: MP4 or MKV with H.264/H.265 video; AAC or PCM audio
- Sample rate: 16 kHz mono WAV for ASR is a safe standard; 48 kHz sources are fine before downmixing
- Loudness: normalize to about −23 LUFS for broadcast or −16 LUFS for online video; keep headroom
- Signal-to-noise: reduce hiss, hum, and room noise to improve SNR
- Channel layout: export isolated dialogue where possible, plus a music/effects stem
- Timebase: convert variable frame rate to constant frame rate for stable timestamps
Example ffmpeg commands:
Convert to constant frame rate and extract mono WAV
ffmpeg -i input.mp4 -r 30 -filter:a "aformat=sample_fmts=s16:sample_rates=16000:channel_layouts=mono" output.wav
Gentle high-pass/low-pass plus light denoise
ffmpeg -i input.wav -af "highpass=f=50,lowpass=f=10000,anlmdn=s=0.001:p=0.003:r=0.01" cleaned.wav
Loudness normalization for web
ffmpeg -i input.wav -af "loudnorm=I=-16:LRA=11:TP=-1.5" loudnorm.wav
When I have crosstalk or music under speech, I export dialogue, music, and effects separately, plus a composite for reference. If speakers overlap, I mark overlapping regions or plan diarization in the next step to separate speakers during transcription.
For low-volume speakers, I normalize, then apply gentle compression (e.g., 2:1) to avoid clipping. If the room is boomy, I use a narrow notch filter to tame resonance rather than heavy denoise that can smear consonants.
Transcribing and translation
Automatic speech recognition sits at the core. I can go open source (e.g., Whisper/WhisperX) for cost control, parameter access, and word-level timing, or choose a managed ASR for simpler pilots, built-in diarization/punctuation, and operational SLAs. The decision is mostly cost, control, and compliance. For long-form ASR trade-offs and Whisper degradation patterns, see https://amgadhasan.substack.com/p/sota-asr-tooling-long-form-transcription.
Features that matter for downstream quality:
- Diarization (who spoke when) so I can map speaker labels to the right cloned voices
- Punctuation and casing to reduce later correction
- Accurate timestamps (word/phrase) for sync to picture
- Custom vocabulary for brand names, product terms, and acronyms
- Batch and streaming modes, depending on the workflow
I run a tight loop:
- First pass: ASR with a sensible parameter set.
- Post-edit: a lightweight language model corrects minor errors in context; I guide it with a short prompt listing key terms and style rules.
- Domain glossary: I inject preferred spellings for product and brand terms.
External voice activity detection helps on long audio. A VAD such as Silero can split audio into speech-only chunks before ASR, reducing false positives and repetition. I run VAD on a file that meets its input rules, then apply the cut list to the original high-quality audio before transcription. That keeps timestamps stable and avoids GPU memory issues on long segments.
For higher accuracy, I layer three tactics:
- Domain glossaries: inject custom vocabulary and ask the model to prefer those spellings.
- Prompting for post-editing: provide a one-sentence video context, a local context window, and rules like “no added facts, keep timings.”
- QA loops: sample 5-10% of lines for human review, track word error rate on those samples, and iterate only if the metric slips.
Small parameter tweaks also help. For Whisper-style models, a lower temperature, modest beam size, and a higher no_speech threshold reduce repetition. I sometimes let an LLM tune ASR parameters against a scoring script that checks for loops, dropped words, and nonsense fragments; I keep the settings that protect consistency. To reproduce pipelines end to end, see https://github.com/thabiger/learning-python/tree/master/ai-video-language-convertion.
Once I trust the source transcript, I translate it. Two strong choices:
- Neural machine translation (NMT) for speed and clarity on factual text.
- Large language models (LLMs) for tone, idioms, and style prompts.
I often run NMT for a first pass, then ask an LLM to polish jargon, tone, and brand voice guided by a short style card. Context matters: sentence-level translation is quick but can miss mood; paragraph-level context preserves references and politeness levels. For long scripts, a sliding window keeps the model aware of 2-3 sentences before and after the current line without bogging down.
To balance quality and speed:
- Subtitles: latency often dominates; sentence-level passes are usually fine.
- Dubbing: tone and rhythm matter; I take extra time to preserve context and cadence.
Recent tactics worth borrowing:
- Let an LLM infer do’s/don’ts from a few aligned examples, then apply those rules lightly across the run.
- Evaluate newer MT/LLM checkpoints weekly on my own content; keep the best for fluency and terminology.
- Use automatic quality estimation (e.g., COMETKiwi, BLEURT) to flag weaker sentences without reference translations.
- Protect brand names and technical terms with tags so they pass through unchanged, and ask for idiomatic rather than literal translations where needed.
Text-to-speech and voice cloning choices
This is where the translated script becomes human-like audio. I think in three model families:
- Multilingual TTS models: trained on many languages, good for steady delivery and consistent pronunciation across markets.
- Zero-shot cloning: copies a voice from a very short sample; fast to scale; better for shorter clips.
- Flow-based vocoders and similar decoders: produce smooth prosody and strong text-speech matching; ideal when I want studio-grade output.
Consent comes first. I only clone voices I own or have written permission to use. I store that consent, link it to audio assets, and restrict access to voiceprints and samples.
Few-shot vs zero-shot in production:
- Zero-shot: fastest to launch, minimal prep, good for pilots and internal training videos, but may drift on long recordings or tricky names.
- Few-shot: needs a handful of clean samples per voice and per language, more setup, yet yields steadier pacing, better breath sounds, and fewer misreads.
As a frame of reference, NVIDIA’s Magpie family illustrates common trade-offs. For an overview of the architecture across variants, see the figure below.
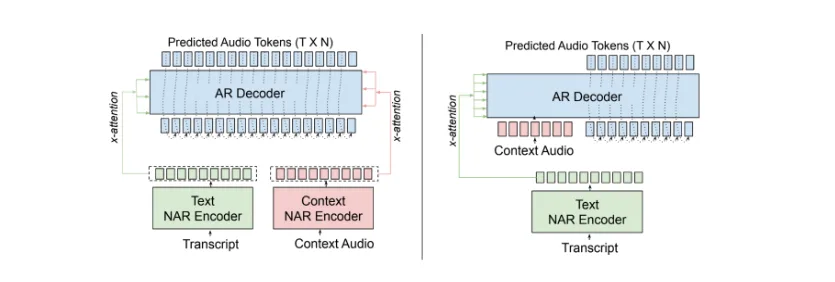
Magpie variants at a glance:
- Magpie TTS Multilingual: streaming, supports major languages, tuned for text adherence; low latency on supported GPUs.
- Magpie TTS Zeroshot: streaming, English-focused, can condition on about 5 seconds of audio; ideal for interactive agents.
- Magpie TTS Flow: offline flow-matching decoder for studio dubbing and narration; higher fidelity, strong text-speech matching.
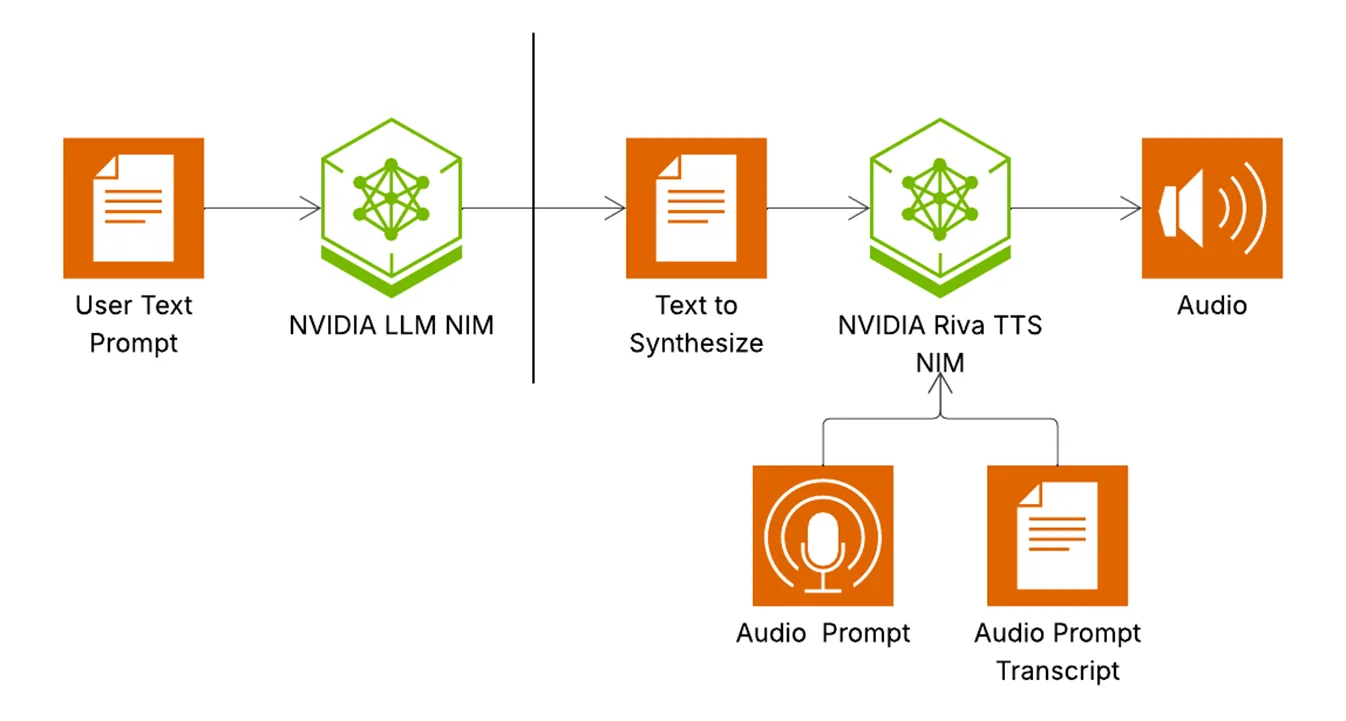
My rule of thumb:
- Real-time or near-real-time across languages: a multilingual streaming model.
- Quick pilots or interactive agents: zero-shot streaming.
- Flagship videos with time for post: a higher-fidelity offline decoder.
Syncing audio with picture
Once I have the generated audio, it must line up with the visuals. Forced alignment tools map words or phonemes to timecodes so I can add short silences, stretch or compress phrases slightly, and keep lip movements believable. Practical steps:
- Get phoneme or word timings from a forced alignment tool (e.g., Montreal Forced Aligner, aeneas, or timing output in WhisperX).
- Compare target duration to the original clip; apply light time-stretching when needed.
- Insert or trim silence around breath points, not mid-word.
- If translation alters speech rate, I rewrite a line to fit on-screen action rather than over-compressing audio.
Visual checks matter. In my editor, I place the original waveform, the music/effects stem, and the cloned voice track on separate lanes. I scrub scene by scene, watch mouth closes on plosives (p, b), and make sure timings land there. If a segment drifts, I split it into two or three sub-segments and retime each lightly. A bit of micro-editing avoids the uncanny moments later. For automation examples that generate Shotcut projects and align segments, see https://github.com/thabiger/learning-python/tree/master/video-editing.
Safety and governance
Voice cloning is powerful, so process and control matter:
- Consent and identity: capture written permission for each use case and language; verify identity; keep an audit trail.
- Rights scope: define allowed purposes, usage limits, and expiration dates.
- Watermarking/provenance: watermark synthetic speech or tag metadata; store hashes; log inputs, outputs, model versions, and timestamps.
- Access controls: lock models to approved voiceprints, rate-limit inference, and require signed requests.
- Brand guardrails: simple rules for what cloned voices cannot say (e.g., financial or medical advice).
- Detection partnerships: use synthetic-speech detection signals in monitoring.
Laws vary by region (e.g., GDPR in the EU; state biometric/privacy laws like Illinois BIPA in the US; evolving AI-specific regulations). I run a quick legal review before large-scale use. For B2B content, I keep a short release protocol: confirm consent, target languages, style guide, watermarking, and approvals from the content owner. For broader practices, see Trustworthy AI and related detection work with Pindrop.
Reference implementation: NVIDIA Riva TTS
If I want a production-grade stack with control over latency, quality, and deployment, NVIDIA Riva is a solid example. Comparable capabilities exist across other stacks; the point is to own latency targets, deployment model, and QA. For model availability and features, review the pretrained TTS models documentation.
Environment setup
- Install recent NVIDIA drivers and Docker.
- Pull Riva images from NVIDIA NGC.
- Start the speech microservices with the Riva startup script.
Model selection
- Need multilingual streaming with strong text adherence: Magpie TTS Multilingual.
- Need fast English cloning from a short sample: Magpie TTS Zeroshot.
- Need studio-grade output and can tolerate offline generation: Magpie TTS Flow.
Sample inference code (Python, Riva Speech API)
import riva.client
from riva.client import Auth, SpeechSynthesisService
auth = Auth(uri="riva.server:50051", use_ssl=False)
tts = SpeechSynthesisService(auth)
req = riva.client.SynthesizeSpeechRequest(
text="Welcome to our product walkthrough.",
language_code="en-US",
encoding=riva.client.AudioEncoding.LINEAR_PCM,
sample_rate_hz=22050,
voice_name="magpie_en_us_multilingual",
enable_spk_conditioning=True,
# For Zeroshot or Flow with cloning, pass speaker audio:
# speaker_audio = open("five_seconds.wav", "rb").read()
)
resp = tts.synthesize(req)
with open("output.wav", "wb") as f:
f.write(resp.audio)
Deployment options
- On-prem for lowest latency and full data control (common in regulated environments).
- Cloud GPUs for elastic scale and bursty workloads.
- Hybrid: on-prem for production, cloud for offline batch dubbing.
Performance notes
- GPU class matters: L4/A10-class handle low-latency streaming at meaningful concurrency; T4s work for lighter loads.
- Throughput often scales linearly with replicas on longer audio. Monitor GPU memory and CPU I/O, not just utilization.
- Latency targets: streaming models can stay under about 200 ms to first audio; offline flow-based jobs run longer but produce higher fidelity.
A pragmatic 30-60-90 plan
- Days 1-30: pilot
- Pick one language pair and one voice.
- Build prep → ASR → translation → TTS on a single GPU.
- Define a quality bar: MOS-style human ratings, error counts per minute, and a timing-drift budget.
- Days 31-60: productionize
- Add diarization/VAD, audit logs, watermark outputs.
- Containerize; add CI checks and a canary batch on each model update.
- Expand to three languages and two voices; measure cost per finished minute.
- Days 61-90: scale and tune
- Introduce a higher-fidelity decoder for flagship videos.
- Add automatic translation quality estimation.
- Train a light pronunciation lexicon for hard names.
- Set SLOs for latency, failure rate, and review turnaround.
Get started resources: Riva Quick Start Guide – Speech Synthesis, NVIDIA NIM, NVIDIA LLM NIM, NVIDIA AI Enterprise, and Request access for gated models.
Further reading
- NVIDIA Riva
- pretrained TTS models documentation
- Riva Quick Start Guide – Speech Synthesis
- Magpie TTS Multilingual, Magpie TTS Zeroshot, Magpie TTS Flow
- NVIDIA NIM and NVIDIA LLM NIM
- NVIDIA AI Enterprise
- Trustworthy AI and Pindrop
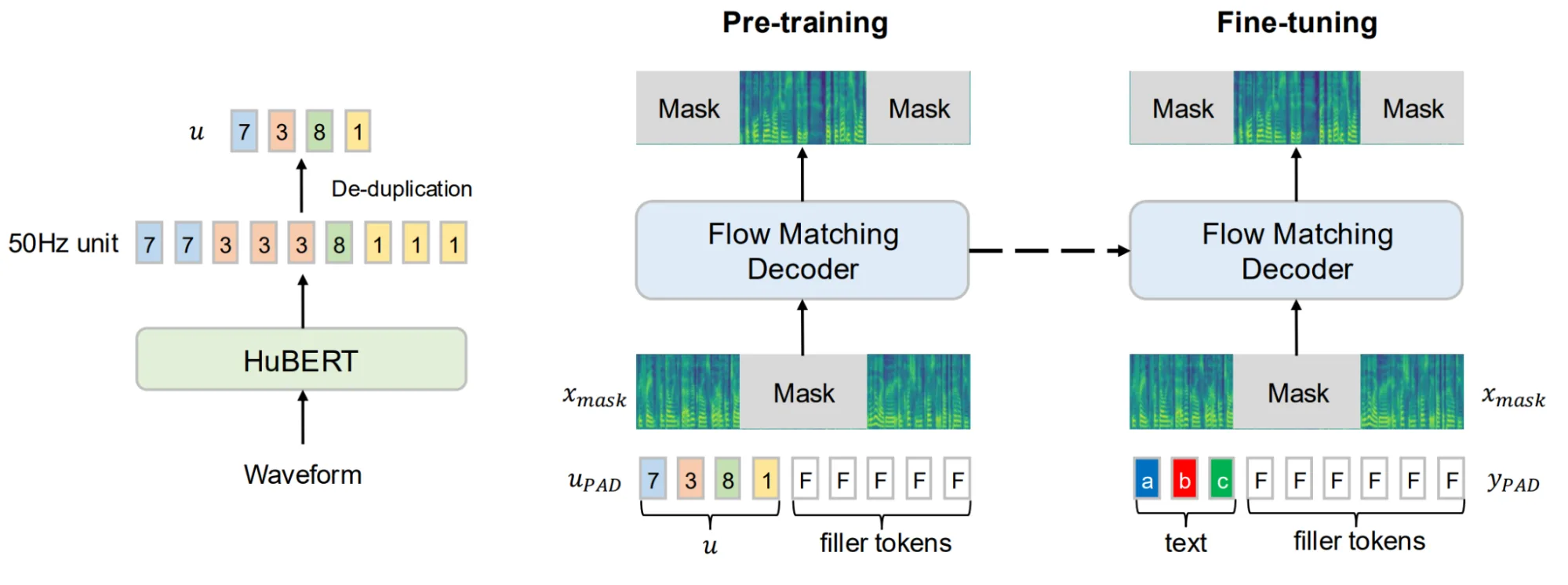
- Direct Preference Optimization (DPO)
- HuBERT
- E2 TTS, alignment-aware pretraining, modified CFM loss, encoder-decoder transformer architecture
- https://amgadhasan.substack.com/p/sota-asr-tooling-long-form-transcription
- https://github.com/thabiger/learning-python/tree/master/ai-video-language-convertion
- https://github.com/thabiger/learning-python/tree/master/video-editing
Bringing it together
The workflow pays off when each stage feeds the next cleanly. Better prep yields cleaner transcripts. Cleaner transcripts produce stronger translations. Strong translations unlock natural speech that still sounds like the speaker, in the target language. With light human review and safety guardrails, I can ship multilingual voice cloning at speed, preserve trust and tone, keep costs predictable, and avoid rework in week two.



.svg)

.svg)
.svg)