
Why synthetic data matters now
Most B2B service leaders do not want a lecture on data theory. You want clarity, speed, and a plan that does not eat your week. Synthetic data gives teams room to move fast without putting real customers, partners, or financial records at risk. It looks and behaves like production data, yet it contains no real people. Used well, it trims lead times, cuts compliance headaches, and helps models learn faster. Used poorly, it can mislead. I will sort the signal from the noise and keep this practical.
Synthetic data is AI-generated data that mirrors the patterns, schema, and behavior of your real data but does not store actual identities. I treat it as a safe stand-in that still delivers outcomes when privacy, speed, and experimentation matter at the same time.
Where synthetic data pays off
Here are high-value B2B scenarios where synthetic data pays off, with executive-level outcomes and the KPIs that prove it:
- Model training in low-data domains: When rare events matter, like chargebacks, supply chain disruptions, or critical support tickets, synthetic data lets me boost minority classes. Outcomes: better recall on rare classes, fewer false negatives. KPIs: minority-class F1, ROC AUC, recall on priority segments, lift vs baseline on holdout sets. For background, see machine learning and how generative AI models create training data.
- Secure software testing and environment seeding: I can populate dev, QA, and staging with realistic, privacy-safe records. Outcomes: faster release cycles, fewer defects in production. KPIs: test data lead time cut from weeks to hours, defect leakage rate, rework hours saved per sprint.
- CI/CD test data generation: Trigger fresh datasets for each build. Outcomes: tighter feedback loops, consistent test coverage. KPIs: build success rate, flaky test reduction, mean time to repair.
- Data sharing with vendors and partners: Share datasets for integrations, SLAs, or proofs of concept without a heavy legal review cycle. Outcomes: quicker partner onboarding, lower compliance risk. KPIs: contract turn time, number of approved partner datasets, audit findings avoided.
- Scenario simulation for risk and planning: Generate what-if scenarios for cash flow, capacity, fraud, or incident response. Outcomes: stronger readiness, better allocation. KPIs: scenario coverage rate, time-to-decision, forecast error reduction. Related reading: generative AI data analytics and 15 Generative AI Enterprise Use Cases.
- Synthetic customer journeys for analytics: Create end-to-end journeys that preserve funnel shape, seasonal patterns, and cohort behavior. Outcomes: sharper marketing mix decisions, better attribution, cleaner sandboxing for BI. KPIs: model fit vs production, attribution stability, time saved on data requests.
What ties these together is time-to-value and risk control. When synthetic data is part of the workflow, teams move from waiting on redacted exports to running experiments on demand. That speed shows up in the numbers. For a scan of current tools, see 9 Best Synthetic Data Software.
Masked vs synthetic: making the call
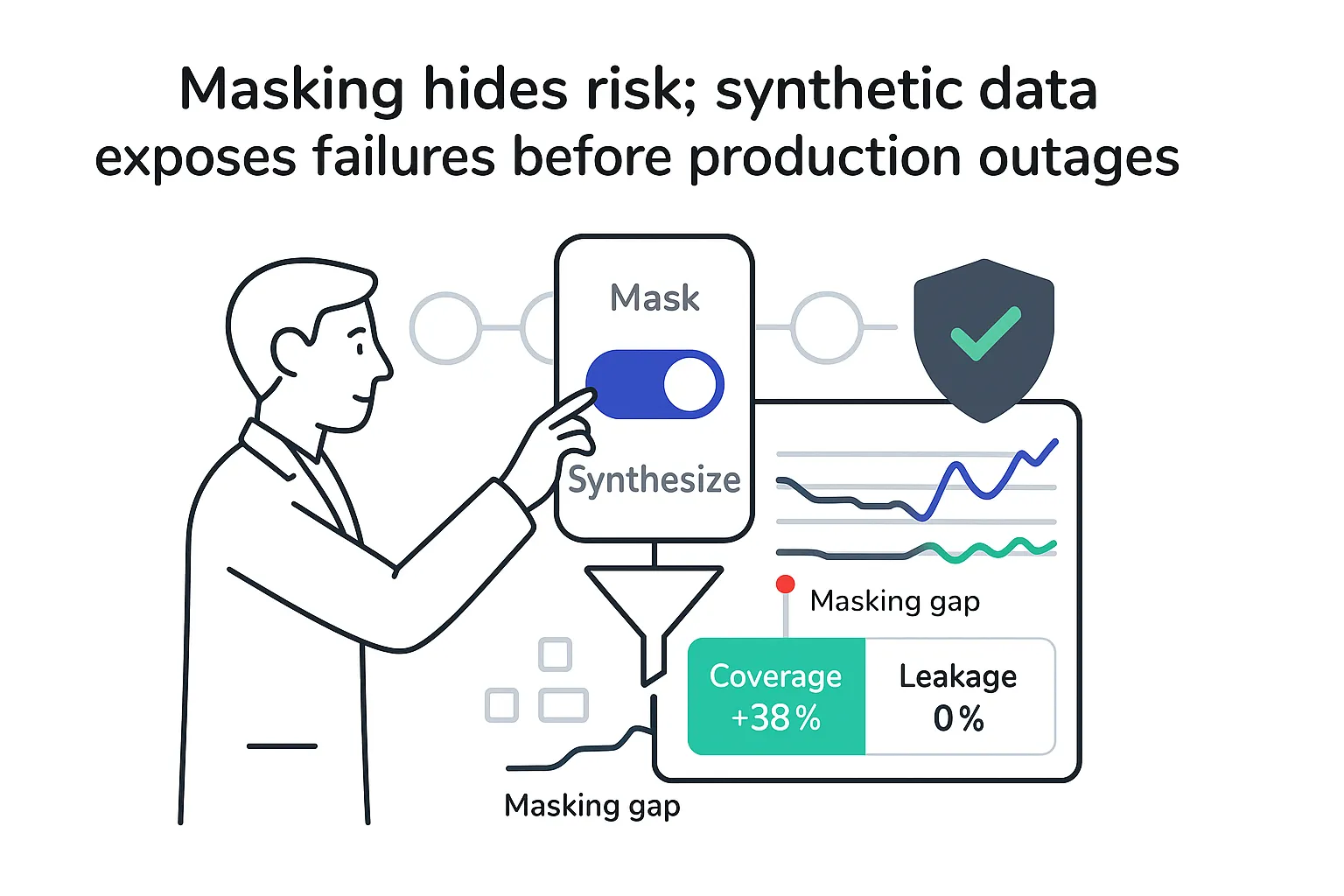
Both synthetic data and masked data aim to protect sensitive information, but they do it in different ways.
- Privacy guarantees: Masking keeps records from production while changing sensitive fields. Re-identification risk depends on technique. Tokenization and encryption help, but linkage attacks can still cause trouble. Synthetic data builds new records, which lowers re-identification risk when generation is done correctly and privacy is tested. For definitions, see Data Masking and Tokenization, Obfuscation, Anonymization, & Masking.
- Utility: Masked data preserves exact structure and referential integrity, which is handy for late-stage UAT. Synthetic data can match distributions and correlations and can be tuned to improve class balance, edge cases, or stress tests.
- Schema fidelity: Masking stays close to the original schema and constraints. Synthetic data must be configured to maintain multi-table keys, temporal ordering, and business rules.
- Maintenance overhead: Masking rules often grow brittle across schema changes. Synthetic data can be rebuilt as schemas evolve, though it needs its own governance.
Compliance context:
- GDPR: Data minimization and purpose limits matter. Masked data may still be treated as personal data if re-identification is possible. High-quality synthetic data that cannot map back to people can be considered out of scope for many GDPR provisions, subject to legal review.
- HIPAA: Safe Harbor and Expert Determination routes exist. Synthetic data used in healthcare analytics often passes Expert Determination when generation and testing are documented.
- PCI DSS: Payment data needs strict control. Masking and tokenization remain standard for transaction systems. Synthetic data helps with testing and vendor sandboxes without card data.
Quick decision flow in plain words:
- If you must preserve exact referential integrity for UAT or regulatory reporting, start with masking.
- If you need to share data outside your org or create rare patterns for tests, use synthetic data.
- If governance maturity and risk tolerance are low, blend masking for a small slice and synthetic data for wider use.
- If your data is PII-heavy and you want strong privacy by design, synthetic data usually wins.
Examples:
- PII-heavy CRM: Use synthetic data for partner demos and internal training. Keep a masked subset for UAT.
- Healthcare PHI: Use synthetic data for research and analytics sandboxes under Expert Determination. Keep masked data only where audits require strict lineage to originals.
- Financial transactions: Use masking or tokenization for any work near payments systems. Use synthetic data in development, vendor testing, and stress scenarios.
Fully vs partially synthetic: trade-offs and measurement
Fully synthetic data: Every record is generated. No original rows exist. This is often built using GANs, VAEs, tabular transformers, copulas, or rule-based engines with constraints. I use this when privacy is paramount or real data is scarce.
Partially synthetic data: A real dataset remains the backbone while selected fields are replaced. Think multiple imputation, regression-based fills, or local generative models only for sensitive fields. I use this when I need anchors that mirror production.
Trade-offs:
- Privacy: Fully synthetic usually delivers stronger privacy, especially when generation is audited with privacy tests. Partially synthetic can still carry linkable signals if not handled carefully.
- Realism and structure: Partially synthetic keeps hard-to-rebuild relationships intact. Fully synthetic needs thoughtful modeling to retain multi-table keys, time dependencies, and business rules.
- Regulatory and performance impacts: In strict regimes or when sharing outside the company, fully synthetic tends to pass reviews faster. For performance testing that depends on exact relational quirks, partially synthetic can suit better.
How I measure utility and privacy in both cases:
- Utility metrics:
- Downstream model performance on matched tasks: compare accuracy, F1, recall, precision on real holdout vs synthetic-trained models.
- Distribution distance: KS test, PSI, or Wasserstein distance on key features.
- Correlation structure and mutual information preservation across fields.
- Drift vs real data across time windows.
- Privacy metrics:
- k-anonymity and l-diversity checks on quasi-identifiers.
- Membership inference tests to see if the generator memorized records.
- If applying differential privacy, track epsilon and delta and observe utility loss across values.
- Linkage attack simulations with external datasets.
Rule of thumb: when privacy is the hill to die on, go fully synthetic. When relational edge cases in a controlled domain matter most, go partially synthetic or blend the two. For method background, see generative AI models and core algorithms.
Benefits executives notice
- Stronger data privacy and compliance: Synthetic data avoids tying back to real people or accounts. Health researchers can build models on patient-like cohorts without names or dates of birth. A bank can test AML scenarios without moving live transactions into lower environments. Executives care because audit findings go down and legal review cycles shrink. KPI ideas to target: time to legal sign-off cut materially, audit findings trending to zero, restricted data access tickets down significantly.
- Supplements for existing datasets: Many teams run out of rare cases. Synthetic data fills gaps at will. Fraud spikes, seasonal churn, or support surges can be amplified. KPIs: minority-class recall up, model calibration error down, edge-case coverage rising toward target thresholds.
- Accessible test data: Test data provisioning often takes weeks. With generators integrated into CI, teams produce tailored sets in hours or minutes. KPIs: lead time for test data down sharply, UAT cycle time reduced, fewer defects tied to missing data paths.
- Potential cost savings: Buying external datasets or running manual anonymization gets expensive. Synthetic data can replace large chunks of that spend and reduce rework when schemas change. KPIs: spend on third-party data down, engineering hours saved, storage and egress fees reduced thanks to ephemeral generation.
- Built to scale up and down: Generators can produce millions of rows with labels and constraints intact. That makes model training, load tests, and scenario analysis easier. KPIs: training throughput up, time to reach target accuracy down, load test coverage increased across endpoints.
Drawbacks and the guardrails that keep me honest
- Limited transparency: Some generators are black boxes. If I cannot see how the model was trained, blind spots creep in. Mitigation: require model cards, document training data scope, and ship privacy and utility reports with each release.
- Difficulty capturing real-world complexity: Real systems include gnarly outliers, messy joins, and drifting behavior. Generators may miss long-tail patterns. Mitigation: benchmark against real holdouts, add hybrid datasets that mix real structure with generated fields, and refresh synthesis rules on a schedule.
- Bias propagation: If the source data has bias, the generator can repeat it. Mitigation: run bias audits on source and synthetic data, test fairness on key segments, and use constrained sampling to balance outcomes.
- Overfitting and memorization: Generators can unintentionally memorize rows, undercutting privacy and generalization. Mitigation: apply differential privacy where possible, run membership inference tests, and use early stopping and regularization.
- Operational risks: Without governance, a model trained only on synthetic data can ship without a reality check. Mitigation: require human-in-the-loop validation, acceptance criteria for utility, and a rollback plan if metrics degrade.
A simple mitigation playbook I rely on:
- Document data contracts for each table and field that will be generated.
- Add privacy tests to CI, just like unit tests.
- Keep a golden real dataset for benchmarking only.
- Track drift between synthetic and real in production-like telemetry.
- Review bias and utility on a fixed cadence.
For related risk context, see emerging AI cybersecurity attacks.
Technology landscape, integration basics, and the road ahead
Platform landscape (non-exhaustive examples to map the space):
- Tabular-first with privacy scoring and governance: MOSTLY AI, Gretel, Hazy.
- Developer-centric test data and CI/CD: Tonic, GenRocket.
- Multi-entity data products with synthesis options: K2View.
- Visual and sensor data for AI: Synthetaic, DataGen, Synthesis AI. For background on a key use case, see computer vision.
- Simulation engines and digital twins: Unity, Unreal Engine, Nvidia Omniverse.
Selection criteria I watch:
- Data types supported: tabular, time series, images, text, graph.
- Privacy guarantees: documented privacy testing, optional differential privacy, memorization checks.
- Multi-table and temporal support: foreign keys, constraints, sequence order, seasonality.
- Integration: CLI/SDKs, CI/CD plugins, REST APIs, data contracts support.
- Governance and security: audit logs, model cards, lineage, access controls, SOC 2/ISO 27001, customer-managed keys, VPC deployment.
- Pricing clarity: transparent tiers and predictable costs at volume.
- Usability: templates for common schemas, responsive support, clear docs.
Procurement pointer: run a bake-off with one dataset and fixed KPIs. Ask for privacy and utility reports. Test CI integration in a real pipeline, not a demo. For a broader tooling view, see Best Artificial Intelligence Software.
Integration basics that work across DevOps and MLOps
- Environment seeding: On branch creation or nightly builds, seed databases with fresh synthetic data that matches the current schema.
- CI test data generation: For each pull request, produce scenario-specific sets for negative tests, rare flows, and failure injection.
- Data contracts: Define schemas, constraints, and relationships as code so the generator honors them across tables and time.
- Golden datasets: Maintain a small, versioned real dataset for validation only; measure drift and sanity-check performance against it.
- Monitoring utility drift: Compare distribution and correlation metrics between synthetic sets and recent production snapshots; alert when PSI or KS values exceed thresholds.
- Access controls and lineage: Treat synthetic data like production in terms of logging and permissions; keep lineage from source schema to generated assets.
Acceptance criteria before a merge:
- Tests pass with synthetic data across core flows.
- Utility variance vs the golden dataset is within agreed bounds.
- Privacy tests are green with documented thresholds.
- A rollback plan exists if metrics degrade after deployment.
Generative methods you will encounter
- GANs for images and structured data: strong at complex joint distributions; watch for mode collapse.
- VAEs and diffusion models: stable training and diverse samples; diffusion is increasingly relevant for tabular.
- LLM-based tabular generators: schema-aware prompts to create realistic rows and sequences; helpful when text mixes with structure.
- Copulas and rule-based engines: great for known distributions and strict constraints; easy to control and explain.
Risks and safeguards
- Mode collapse: add diversity penalties, use diffusion or ensembles, and monitor coverage metrics.
- Hallucinations that break rules: enforce constraints during generation and run strict validators post-hoc.
- Memorization: use DP-SGD when needed, run membership inference tests, monitor nearest-neighbor leakage.
- Hidden bias: audit at the source and in outputs, adjust sampling, and set fairness targets for model training.
Also see how analytics workflows are evolving with generative AI data analytics.
Bottom line and getting started
Synthetic data shines when speed, privacy, and experimentation matter at the same time. It is not magic; it needs guardrails, metrics, and people who own outcomes. To get moving without the drama:
- Pick one priority use case where delays hurt now, like QA seeding or a model that struggles with rare classes.
- Pilot with a single dataset and a short list of KPIs for utility, privacy, and speed.
- Select a platform based on data types, privacy guarantees, CI fit, and security posture.
- Define utility and privacy thresholds before you begin, not after.
- Run A/B experiments against real baselines and publish results to stakeholders.
- Bake governance into CI so privacy and utility checks run every time.
The mild contradiction I embrace: synthetic data can both simplify and complicate your stack. It removes waiting on approvals and replaces scarce edge cases with on-demand coverage. Yet it also asks for a clear contract with your data and your process. I resolve that tension with a light but steady framework to get the upside without the surprises.



.svg)

.svg)
.svg)