

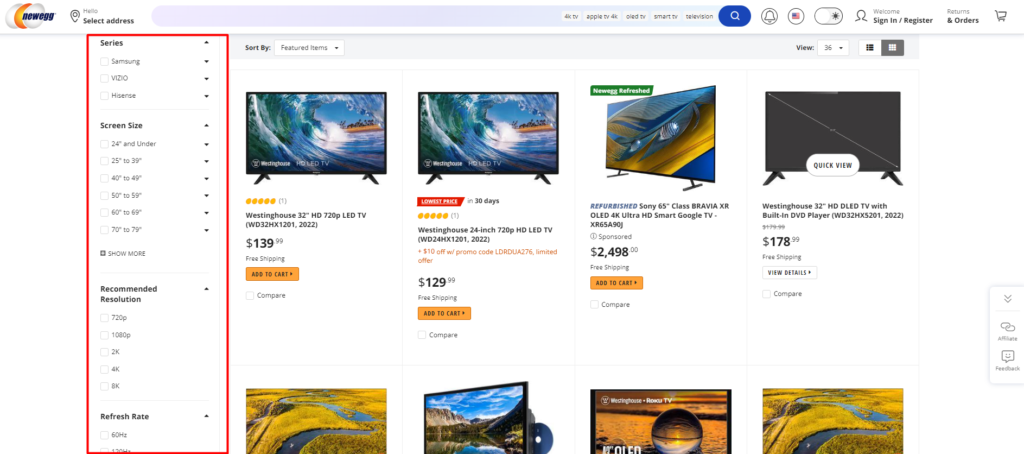
If your category pages feel like a lead machine one week and a traffic drain the next, there is a good chance faceted navigation is the culprit. I treat it as a gift for users - and a frequent source of crawl waste, duplicate URLs, and diluted rankings. The upside is real. So are the risks. CEOs want the math, not magic. Done right, faceted navigation brings high-intent traffic and stronger conversion rates. Done wrong, it burns budget while hiding key pages behind infinite parameters. I want to keep the wins and cut the waste.
Note on scale: crawl budget issues primarily impact large sites; on smaller sites, the bigger risk is duplication and weak relevance signals that blunt rankings (Crawl inefficiency).
Faceted navigation SEO risks: why crawl waste becomes a revenue problem
Here is the blunt version. Faceted navigation can spin up thousands of near-identical URLs. That leads to duplicate content, index bloat, diluted link equity, and crawl traps. Search engines wander through parameter mazes while your money pages wait. The outcome is slower indexation of new offers, weaker rankings for core categories, and higher paid media dependency.
Quick, high-impact fixes:
- Block unbounded facets like sort, view=all, price sliders, and session IDs.
- Restrict the depth of combinations. Two layers cover most search demand; validate with keyword data before allowing three.
- Enforce a single parameter order with redirects, not just canonicals. The same filter stack should resolve to one preferred URL.
- Fix infinite spaces created by pagination plus filters. Page two should not spawn ten variants or repeated parameters.
How I measure progress (weekly):
- Index coverage: shrinking counts of parameterized URLs in Google Search Console.
- Crawl stats: more hits to key categories and fewer to query strings (log files or Crawl Stats in Search Console).
- Impressions and clicks: category and key filter pages rising in Search Console Performance.
- Time to first meaningful improvement: 4-8 weeks for many sites, depending on crawl rate and scope of changes.
Blocking everything is tempting. It can backfire. The smarter path is to allow a short list of high-value combinations and control the rest with robots.txt, meta robots, canonicals, and - where possible - server-level redirects. One critical nuance: if I want a URL removed from the index via noindex, I do not disallow it in robots.txt until after Google has recrawled it and processed the tag (robots.txt blocks crawling, not indexing).
What is faceted navigation: the user filter system that writes your URL state
Faceted navigation is the filter system that lets people slice results by attributes. Think color, size, price, brand, rating, and availability on a product list page. Or, for B2B, industry, service type, location, compliance needs, tech stack, and content type in a resource library. Each filter selection updates the state of the page and usually the URL. If you want a deeper primer on the difference between facets and filtering, this breakdown is helpful.
I keep the cast clear:
- Categories define broad groupings. Shoes, Services, Guides.
- Facets are filter dimensions within a set. Brand, size, industry.
- Filters are selections within a facet. Size equals 10, Industry equals Finance.
- Sorting simply orders the same set. Price low to high, newest first.
Faceted navigation differs from rigid trees. Users can start anywhere, combine filters, and get closer to what they want without starting over. That is why it converts. On the tech side, every choice can create a new state that search engines may try to crawl. That is where smart rules matter.
Faceted URLs: parameters, paths, and why hashes do not count
Faceted navigation writes state into URLs in a few common ways.
Typical patterns:
- Parameter-based: /trainers?color=red&size=xl
- Path-based: /trainers/color/red/size/xl
- Hash-based: /trainers#color=red&size=xl
Key notes:
- Hashes do not create indexable states for Google; fragments are ignored for indexing.
- Normalize parameter order and casing at the server with 301 redirects. /trainers?size=xl&color=red and /trainers?color=red&size=xl should collapse to one canonical URL.
- Use lowercase and consistent encoding; remove empty or duplicate parameters to prevent variants.
- Pagination and filters need guardrails. /trainers?color=white&page=2 is fine. /trainers?color=white&page=2&sort=popular&sort=popular is a trap.
Path vs parameter trade-offs:
- Paths look cleaner and are easier to link, but they require strict routing and canonical discipline.
- Parameters are flexible and easier to control with robots.txt, but they multiply fast if left unchecked.
A B2B example:
- /services?industry=finance®ion=uk
- Or a friendly path: /services/finance/uk
I pick one model as the default and stick with it. Consistency improves crawling and analytics. For implementation specifics, see how to Apply canonical tags effectively to consolidate variants.
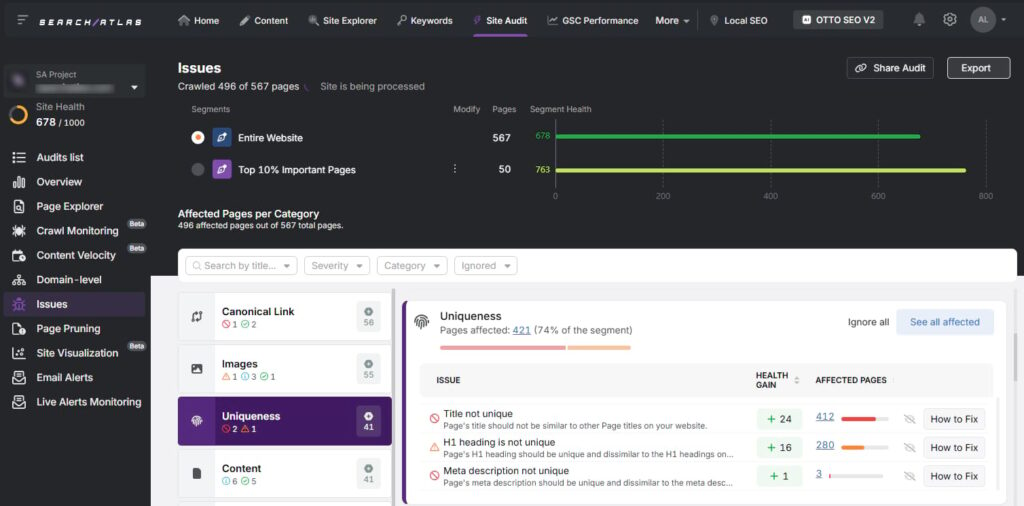
How I spot faceted navigation issues: find bloat fast, then prove impact
You do not need a lab coat to diagnose trouble. A simple sweep with standard tools surfaces most problems. Treat Site: queries as directional, not exhaustive.
Start here:
- Google Search Console Coverage: filter by “Indexed, not submitted in sitemap.” Look for patterns with ?color=, ?size=, ?sort=, view=all, or price sliders.
- Google Search Console Performance: filter by Page and add inurl:? to isolate parameterized URLs. Check impressions and clicks. Lots of crawled pages with thin traffic signals waste budget.
- site: and inurl: queries: site:yourdomain.com inurl:?color= or inurl:view=all or inurl:sort=. Adjust to your facet naming.
- GA4 landing pages: sort by low engagement rate and filter for pages containing “?”. If these pages attract entrances but do not hold attention, flag them.
- A crawler pass (once obeying robots.txt, once ignoring) to extract parameter names and count combinations. Spot infinite paths like ?page=12&sort=price repeated with minor tweaks. A purpose-built Site Auditor helps you segment and prioritize these quickly.
- Log files or Crawl Stats: look for high crawl depth on URLs with parameters and minimal content variety. That is where crawl budget burns.
Helpful patterns and filters:
- Regex for quick screens: [\?&](color|size|brand|sort|view|price)=
- Empty state checks: find URLs with “0 results” in the HTML or a no-products element.
- Canonicalized duplicates: high counts can be fine, but a surge often means unbound faceted navigation. Remember: canonicals are hints, not directives. If in doubt, revisit how you Apply canonical tags.
Red flags that deserve immediate action:
- Infinite “sort” and “view=all” combinations.
- Filters that create different parameter orders for the same selection.
- Facets exposed on pages with no items in stock.
- Pagination mixed with filters that spawn deep, low-value chains.
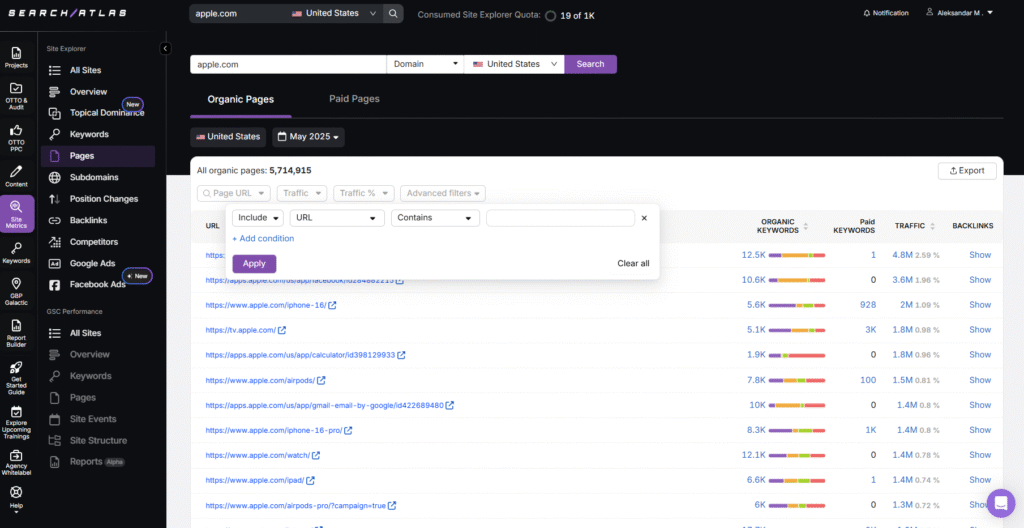
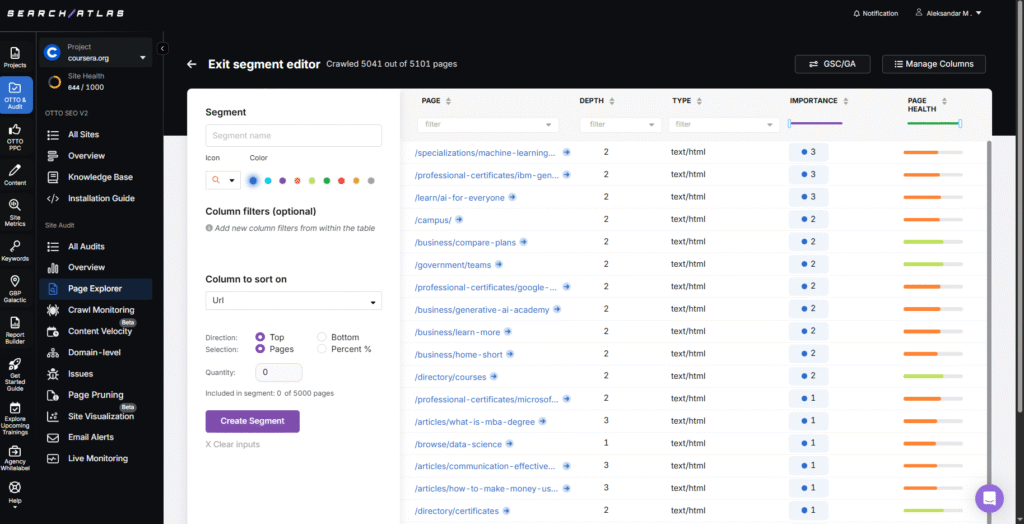
Proven methods for faceted navigation: a simple decision framework that works
I let the market guide what I allow. Index only what people search and what presents unique, helpful value on the page. Everything else should be noindexed, canonicalized, redirected, or blocked from crawling.
Use this playbook:
- Index: combinations that match real search demand and show a strong set of results. Color + material for a category can deserve an indexable page. In B2B, think Industry + Service + Region when you have depth (case studies, proof points) to enrich that page.
- Noindex: utility-only variations. Sort, view density, and quirky mixes that users rarely seek should remain accessible for UX but not indexed. Caveat: over time, Google may crawl noindexed pages less, so do not rely on “noindex, follow” to pass link equity indefinitely; make sure important links also live on indexable pages.
- Canonicalize: near duplicates back to a single parent. Sort orders, presentation filters, or reordered parameters should consolidate signals. When a page is meant to rank, use a self-referencing canonical.
- Redirect: where feasible, 301 variant patterns (parameter order, casing, trailing slashes) to a single preferred form. This prevents endless duplicates and reduces dependence on canonicals.
- Disallow crawl on pure sinks. Session IDs, calendar grids, endless price sliders, and infinite combinations should be out of reach for bots. Do not use robots.txt to deindex; use it to reduce crawl of URLs you never want crawled.
Set rules for depth:
- Cap combinations at two facets for indexable states in most cases; allow three only when queries and content justify it.
- Use a whitelist for the indexable set. If a pair (or trio) of facets holds value, allow it. If not, noindex or block.
Create static landing pages when the data supports it:
- If a combination has real search volume and can support unique content, build a proper landing experience with quality copy, internal links, and appropriate structured data (e.g., ItemList, BreadcrumbList). For B2B, “Finance Compliance Audits in the UK” can host testimonials, process notes, and regional signals.
UX matters too:
- Avoid zero-result pages. Provide fallbacks or a friendly message with nearby filters.
- Use sensible defaults. Do not show every filter at once on mobile.
- Keep persistent URLs so users can share or return to a filtered view.
Internal linking rules:
- Link only to canonical targets. Remove parameters from navigation where you can.
- Avoid exposing infinite combinations through sitewide modules. Elevate only a few high-value filters.
- Do not rely on rel="nofollow" on internal links; fix exposure at the source. For deeper guidance, see this internal linking guide.
Sitemaps:
- Include only canonical, indexable URLs in XML sitemaps. Exclude parameterized states. This helps discovery of the right pages and keeps index signals clean.
One more note on trends. Since the URL Parameters tool in Google Search Console has been retired, site logic carries the full weight. I bake rules into the platform rather than hoping a setting will rescue things later.
Robots.txt
Robots.txt is a gatekeeper for crawl efficiency. I use it to keep bots away from noisy patterns, not to remove pages from the index. For deindexing, meta robots or returning 404/410 is the right approach. And I never block a page in robots.txt if I need Google to see a noindex on it.
Helpful blocks often include sort orders, view=all, price sliders, and session IDs. Keep CSS and JS open so Google can render pages.
User-agent: *
Disallow: /*sort=
Disallow: /*view=all
Disallow: /*sessionid=
Disallow: /*price_from=
Disallow: /*price_to=

I verify the impact in logs or Crawl Stats to confirm that crawlers shift focus to core categories and approved filters. One caution: if I block discovery too early, I might hide issues from my own audits. I run a short test crawl with robots ignored in a staging environment, then re-enable rules. Measure, then adjust. For a practical on-page check of directives, use an On-Page Audit Tool.
Meta robots noindex
Meta robots noindex works well for low-value combinations that users still need for browsing. I start with “noindex, follow” so link discovery continues as pages drop out of the index, but I also ensure those links exist on indexable pages because Google may eventually crawl noindexed pages less.
A simple lifecycle:
- Mark a filter state as “noindex, follow.”
- Watch Search Console to confirm removal from the index.
- After cleanup, consider removing internal links to that state if it is no longer needed.
- If a noindexed state earns good engagement and search demand changes, replace the meta robots tag with a self-referencing canonical and treat it as an indexable asset.
Quality assurance tips:
- Validate that templates respect the directive on all variations.
- Spot-check with the URL Inspection tool.
- Confirm that paginated variants past page one are “noindex, follow” when they do not add value.
Learn more about Meta Robots tags and how they work alongside robots.txt and canonicals.
Canonical tags
Canonical tags are the glue that keeps duplicates from spreading signals thin. I use them to consolidate sort orders, parameter reorderings, and presentation filters. When a combination does not create a unique set worth ranking, canonical back to the parent category or the cleanest version of the filtered state. When a page is meant to rank, use a self-referencing canonical.
Keep these rules tight:
- Ensure internal links point to canonical targets. Linking to non-canonical URLs sends mixed signals.
- Keep hreflang and canonical in sync. Do not canonical across languages or regions unless the content is truly the same target.
- Avoid circular canonicals or chains. Every page should point to itself or the single preferred version.
- Prefer permanent redirects over canonicals when you are collapsing purely technical variants (e.g., parameter order, trailing slashes).
Handling pagination with filters:
- Pages beyond the first rarely deserve indexation. Use “noindex, follow” past page one, and consider a canonical to page one when content is a continuation.
- If each paginated page has distinct items you want crawled, keep the canonical self-referencing but retain “noindex, follow.” Avoid “view=all” as an indexable alternative; it often harms performance on large sets.
A small but important reminder: canonicals are suggestions, not absolute rules. That is why linking, template logic, redirects, and rules for filters must agree. I bring them into one story.
Final thoughts for busy leaders who care about ROI. Faceted navigation can be an engine for high-intent queries when I build a short list of indexable combinations and treat them as real landing pages. It can also be a sinkhole that hides valuable work behind parameter chaos. The difference lives in the rules. Set a cap on depth. Whitelist what deserves a ranking shot. Redirect and canonicalize technical variants. Block noisy patterns. Use meta robots with care. Keep sitemaps clean. Track crawl and index coverage like a CFO watches margins. When the signals tighten up, organic growth feels less random and more like a steady pipeline you can rely on.
For additional context, an expanded version of this perspective appeared on SEJ.



.svg)

.svg)
.svg)