
Open-source vs commercial LLMs for B2B services: how I decide
I want AI that moves the needle without adding chaos. In a B2B services context, the pivotal choice is open-source versus commercial large language models (LLMs). Both can drive real outcomes - higher lead quality, faster proposals, leaner support queues, clearer reporting - so I start by picking the path that fits my timeline, compliance posture, and budget curve without trapping my team in never-ending setup.
I put the model path first on purpose. Many guides leave it until later. Starting here forces everything else - architecture, governance, and measurement - to align with business outcomes, not model hype.
- What I’m optimizing this quarter
- Lead quality: more qualified inbound, fewer junk forms, tighter ICP match.
- Support deflection: higher self-serve resolution, lower ticket volume.
- Proposal velocity: faster RFP drafts, better win themes, shorter cycles.
- CSAT: clearer answers, fewer escalations, consistent tone.
- Time-to-first-value: measurable lift in weeks, not quarters.
A 60-second decision framework I rely on
I choose open source when I need:
- Maximum control, strict data residency, and on-prem or VPC deployment.
- The lowest per-inference cost at sustained, predictable volume.
- Deep customization (prompts, adapters, fine-tuning, inference settings).
- In-house engineering to run GPU infrastructure, observability, and MLOps.
I choose commercial when I need:
- The best quality out of the box and the fastest time-to-value.
- Advanced reasoning, long context windows, and structured outputs.
- Enterprise SLAs, safety tooling, privacy commitments, and mature ecosystems.
- Low ops lift, rapid experimentation, and built-in governance features.
In practice, I map "when to choose each" against my context:
- Open source: on-prem/VPC, strict privacy, custom workflows, high steady volume, fine-tuning on private data, strong MLOps maturity.
- Commercial: variable or low volume, tight deadlines, long context, vendor SLAs, minimal ops, fast iteration, built-in guardrails.
What LLMs are - and how I adapt them
LLMs are neural networks trained on text to predict the next token. They power drafting, summarization, extraction, classification, and reasoning. For a succinct explainer, see Cloudflare: What is a large language model?. For background on transformer-based models, this overview is helpful: Springboard on GPT-3 and transformers.
The labels matter:
- Open source: code and weights available under an open license.
- Open weight: weights available but with use restrictions.
- Proprietary: closed models accessed via APIs or managed services.
How I adapt them:
- Full pretraining: rarely feasible for enterprises.
- Fine-tuning: adjust a base model with my data for target tasks.
- Prompt engineering: structure prompts and system messages for consistent behavior.
- RAG: retrieval-augmented generation that injects fresh, private context at query time.
Most enterprise wins combine prompt engineering, RAG, and light fine-tuning. I reserve heavier training for narrow, high-ROI use cases where the lift justifies the added ops and governance.
When open source fits best
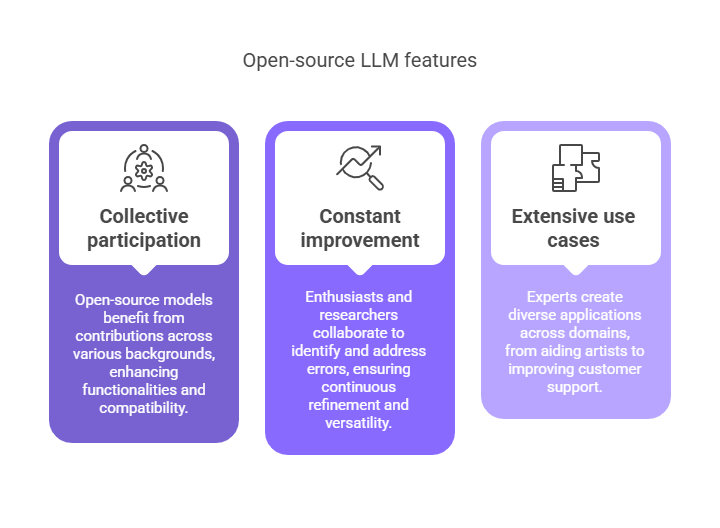
Licensing matters
- Permissive (Apache 2.0, MIT): flexible for commercial use.
- Restricted (e.g., community licenses): read terms on redistribution, usage caps, and derivatives. I confirm with legal before rollout.
Pros
- Transparency: I can review what runs in my environment.
- Privacy control: prompts and outputs can stay inside my perimeter.
- Cost efficiency at scale: per-inference cost drops when utilization is high and volume is steady.
- Customization: full control over prompts, adapters, fine-tuning, and inference settings.
Cons
- Infra and ops: GPU capacity planning, autoscaling, observability, patching.
- MLOps maturity: CI for prompts, eval pipelines, canarying, and rollbacks.
- Security hardening: secrets, KMS, network segmentation, supply-chain checks.
- Talent: ML, DevOps, data engineering, and analysts to run evals and watch drift.
Where it shines in B2B services
- On-prem knowledge assistants that must never leave my network.
- PII-safe document processing with in-house redaction and audit logs.
- RFP drafting on private libraries of past bids and win themes.
- Call-note summarization that stays inside my compliance boundary.
- Contract review tied to a proprietary clause library.
Skills and building blocks I plan for
- Skills: DevOps for GPUs/queues, MLOps for evals/versioning, data engineering for RAG pipelines and vector stores, security for IAM and network controls.
- Components: model gateway/router, model server, vector database, guardrails, policy engine, and end-to-end observability (latency, errors, and cost).
When commercial LLMs fit best
What I usually get
- Strong reasoning on complex tasks and long inputs.
- Managed APIs/SDKs with function calling and structured outputs.
- Enterprise SLAs, incident response, and role-based access.
- Zero-retention options and private endpoints to tighten data handling.
- Mature ecosystems for prompt governance, safety filters, and analytics.
Pros
- Fastest time-to-value with polished capabilities.
- Better performance on advanced reasoning and very long context.
- Dedicated support and uptime targets, including latency SLOs.
- Rich safety, content moderation, and monitoring options.
Cons
- Cost at scale if usage grows quickly.
- Limited control over model internals.
- Vendor lock-in risk and migration friction (I reduce this by abstracting interfaces and tracking per-request metrics).
Leading examples (evolve quickly)
- OpenAI GPT-4.1 and GPT-4o.
- Anthropic Claude 3.5 and 3.1.
- Google Gemini 1.5 family.
- Cohere Command R and Command R+.
B2B services use cases I prioritize
- Proposal strategy and executive summaries that benefit from higher-order reasoning.
- Marketing content QA and brand tone checks.
- Multilingual support across client geographies.
- Complex data extraction with structured JSON output.
Privacy and data handling I review
- Zero-retention modes, regional endpoints, and data residency options.
- Terms governing training on my data.
- Private networking paths (e.g., VPC-style peering) for stricter control.
The real economics: TCO and break-even math
I group total cost of ownership into five buckets:
- Build: setup, license review, security architecture, networking, and integrations.
- Run: compute or tokens, hosting, storage, vector search, egress. Open source includes GPU spend or amortized hardware; commercial is usually per-token plus any platform fees.
- People: ML/DevOps, app engineers, prompt engineers, analysts for evals, and project management.
- Governance: audits, eval pipelines, red-teaming, monitoring, documentation, and change control.
- Risk: downtime, model drift, data leakage, and incident response.
A mini-calculator I use
- Tokens per request × requests per month = total tokens.
- Variable cost = total tokens ÷ 1,000,000 × price per million tokens.
- Total monthly TCO = variable cost + monthlyized fixed costs (people, governance, infrastructure).
Sample scenario for a B2B service firm
Assumptions
- 1 million requests/month.
- 1,000 tokens/request on average.
- Total tokens: 1 billion/month.
Commercial model
- Average blended price: 10 dollars per million tokens.
- Variable cost: 1,000 million × 10 = 10,000 dollars/month.
- Fixed ops: minimal - assume 5,000 dollars for integration and monitoring.
- Estimated monthly TCO: about 15,000 dollars.
Open-source model
- Amortized infra and people: 25,000 dollars/month for GPUs, storage, security, and a small team portion.
- Variable inference: 2 dollars per million tokens.
- Variable cost: 1,000 million × 2 = 2,000 dollars/month.
- Estimated monthly TCO: about 27,000 dollars.
Break-even logic
- Fixed cost difference: 25,000 − 5,000 = 20,000 dollars.
- Per-million token difference: 10 − 2 = 8 dollars.
- Break-even volume: 20,000 ÷ 8 = ~2,500 million tokens/month.
My takeaway: at low or spiky volume, commercial pricing is often cheaper and faster to capture. At very high, steady volume with capable in-house teams, open source can win on variable cost - if I keep utilization high and latency within targets. Prices and context usage change, so I re-run this math quarterly.
Security, performance, and a pragmatic hybrid
Compliance framing I align to
- SOC 2 and ISO 27001 for policy, access control, audit logging, change management.
- HIPAA for BAAs, encryption in transit/at rest, and strict PHI handling.
- GDPR/UK GDPR for data residency, consent, right to erasure, DPIAs.
- CCPA for consumer rights, deletion, and restricted sharing.
Controls I plan and document
- Data residency and segregation by client or region.
- Encryption, key management, and rotation schedule.
- Least-privilege access with SSO and step-up auth for sensitive actions.
- Audit logs for prompts, retrieved context, outputs, and actions taken.
- DLP and PII redaction before prompts hit a model.
- Safety filters, content policy enforcement, and periodic red-teaming.
- Model governance: model cards, versioning, approval workflows, and prompt lineage.
How the model path intersects with compliance
- Open source: full control of storage and traffic on-prem/VPC; I own BAAs, DPIAs, and audit evidence.
- Commercial: zero-retention modes, private endpoints, and vendor SLAs; I still own consent, minimization, and access control.
Performance and benchmarking I trust
Evaluate with representative tasks and metrics, then weight by business impact. For deeper comparisons across models, this overview can help: comparison of all major models.
- Representative tasks: summarization, extraction, classification, long-form generation, retrieval-heavy RAG.
- Metrics: accuracy/F1, faithfulness, p95 latency, cost per 1,000 tokens, deflection rate where relevant.
- Weighted scorecard: I weight by business impact, not just raw scores.
- Data: public benchmarks (e.g., MMLU, GSM8K, HellaSwag) for baseline; domain data (contracts, support logs, proposals) for decisions that matter.
- Practices: human review on a sample set, track failures and near misses, monitor drift and trigger re-evals.
A hybrid I use when stakes vary
- Routing: open source for inexpensive, PII-heavy, or latency-critical tasks; commercial for complex reasoning and very long context.
- Fallback: if the primary model errors or exceeds latency SLOs, retry on a backup; if confidence is low, trigger a human review or a second-model vote.
- Budget guardrails: if spend exceeds a threshold, throttle optional tasks or switch routes.
Micro case studies for B2B services
- Support deflection: route common, PII-heavy FAQs to an on-prem open-source LLM with redaction and logging; send complex escalations to a commercial model. Result: lower cost per interaction with higher CSAT.
- Proposal automation: use a commercial model for executive summaries and win themes, paired with an on-prem RAG pipeline that fetches client history and pricing tables. Result: faster proposals with a clean privacy story.
- Research and drafting: open-source LLMs summarize internal notes safely; commercial models handle long-context competitor reports and multilingual checks. Result: fewer manual hours and more strategic focus.
The choice is not binary. I start where I can win in the next quarter, keep my compliance story tight, and design for optionality so I can evolve toward the volume and control I expect later.



.svg)

.svg)
.svg)