
If you run a B2B service company, your website isn’t a content farm. It’s a tight set of money pages, case studies, and a blog that punches above its weight. That’s exactly why log data matters. It shows how bots actually spend time on your site, not how you might assume they do. Clean up crawl waste, nudge bots toward the URLs that sell, and you’ll see faster discovery and steadier indexing. Sounds technical. It is. But it’s also direct, measurable, and a relief for leaders who want results without babysitting.
Crawl budget quick wins with log file analysis for SEO
Here are actions to prioritize in the first month. These moves trim waste and push bots toward pages that win pipeline. Set targets, track weekly, and you’ll see lift on the metrics that matter. For background on what Google means by crawl budget, see crawl budget.
Immediate fixes tied to KPIs
- Fix error hotspots. Find URLs with repeated 404, 410, and 5xx hits and fix or remove them. Target: 4xx and 5xx bot hits under 2 percent on most B2B sites.
- Convert stray 302s to 301s. Make redirects permanent where permanence is intended. Fewer loops, less crawl drag.
- Block faceted parameters and calendar pages from crawling. Use robots.txt disallows, reduce internal links to those URLs, and apply rel=canonical or noindex where appropriate. Target: under 10 percent of bot hits to non-indexable URLs.
- Clean up pagination and duplicate paths. Consolidate with 301s and consistent canonicals. Keep a single, clean path per page.
- Remove non-indexable pages from sitemaps. Sitemaps are a crawl guide - don’t invite bots to rooms you keep locked.
- Add accurate lastmod to priority URLs in your XML sitemaps. This encourages faster recrawl of fresh money pages. Target: new or updated URLs discovered within 3 days. See Sitemaps.
- Align canonicals and robots directives. When a canonical points one way and robots rules point another, bots take the long route. Make your directives agree.
What I measure weekly
- Percent of bot hits to non-indexable URLs under 10 percent.
- 4xx and 5xx bot hits under 2 percent.
- Days to first discovery for new URLs at 3 or fewer. Validate with the URL Inspection tool.
- Crawl share to priority pages over 60 percent.
Why this works for B2B sites
- You don’t need more pages. You need the right pages crawled more often.
- Faster discovery of pricing, service, and case study pages improves lead-quality signals.
- Fewer waste hits means bots reach important URLs sooner, especially after releases.
30–60 day plan
- Days 1–30:
- Export bot hits by status code and fix the top error offenders.
- Map all 302s and convert intentional ones to 301s. See Google’s guidance on Redirects.
- Add lastmod to key sitemaps and validate in Search Console.
- Block crawl traps like /search, /calendar, and unneeded parameters via robots.txt and internal linking hygiene.
- Days 31–60:
- Prune non-indexable URLs from sitemaps and remove dead duplicates. Review Canonicalization.
- Rework pagination and canonical logic on long lists.
- Recheck crawl share to money pages - if it’s below 60 percent, strengthen internal links into them.
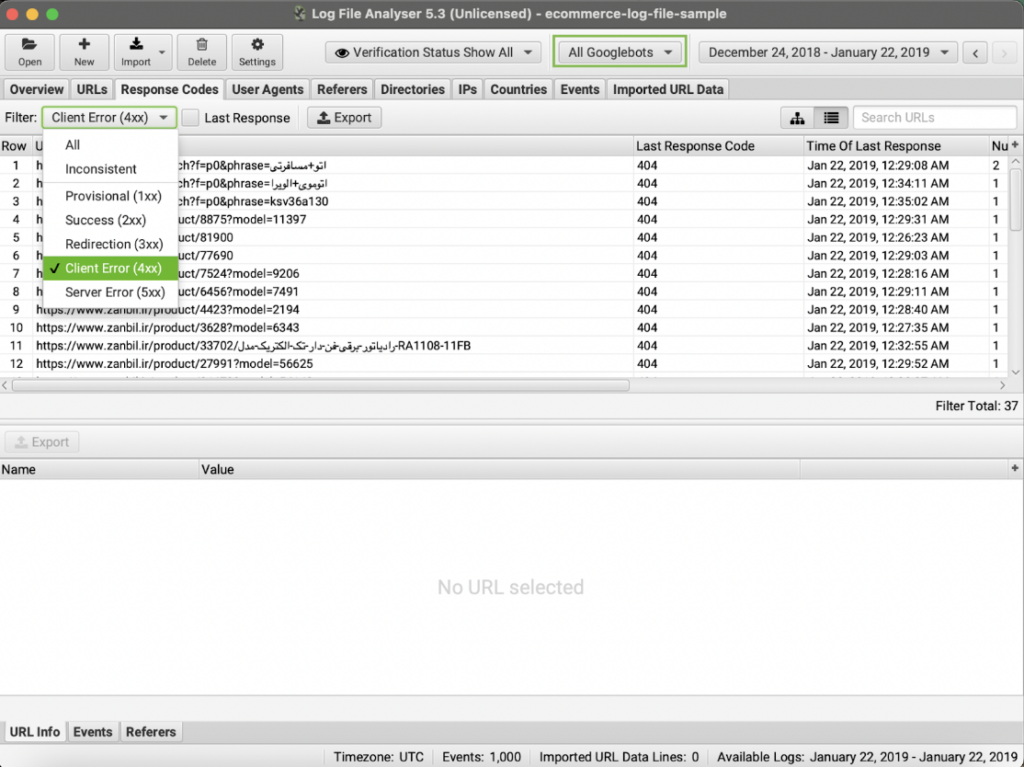
Log file analysis for SEO
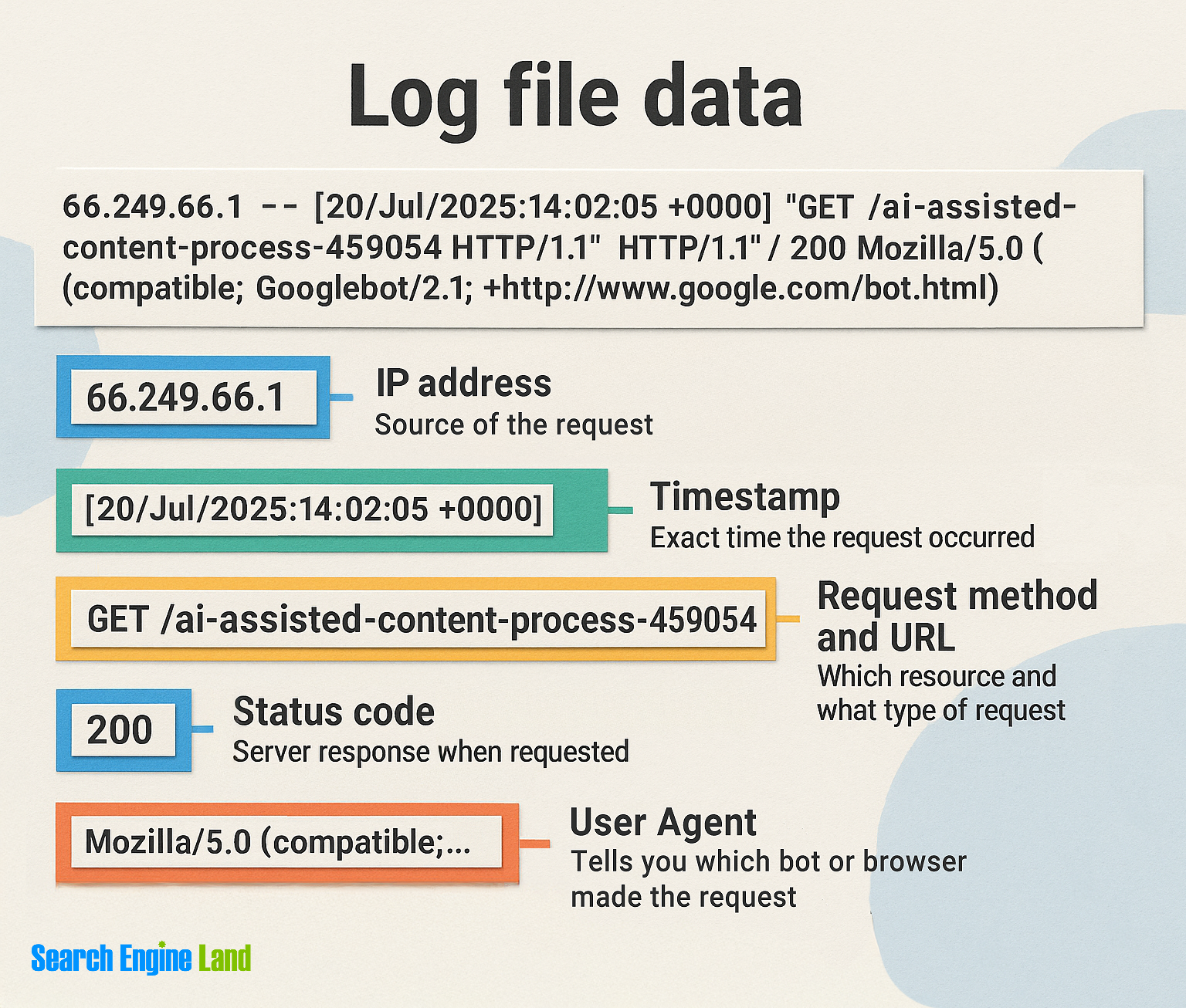
A server log file is a raw record of every request the server receives. Each line captures the timestamp, method, URL, status code, bytes sent, user agent, and often the referrer, host, and IP. Log file analysis for SEO means reading those lines to answer simple questions that move rankings and revenue. Which pages do bots visit most? Which ones never? Where are errors wasting crawl budget? How long do new pages take to be discovered? Are JavaScript files hogging crawl time while the HTML sits ignored?
Why this matters for B2B service sites
- Small site, big stakes. Each service page is a revenue engine. You want proof that bots see it.
- Quick ROI signals. When error hits drop and discovery speeds up, you see it in indexing and rankings.
- Accountability. Raw logs show what happened, not what a crawler thinks should happen.
Map log fields to SEO questions
- IP and user agent. Is it really Googlebot or a spoof? Confirm with reverse DNS and change their behavior notes, or check Google’s published ranges.
- Timestamp. How often is a page crawled? Did crawl frequency drop after a change?
- Method and URL. Are bots spending time on HTML or stuck on assets and parameters?
- Status code. Where are 404, 410, 301 chains, and 5xx responses draining budget?
- Bytes and response time. Are slow, heavy pages eating crawl minutes?
- Referrer and host. How did bots land here, and which host served it? Internal link trails and sitemap hits are clues.
How it ties to crawl budget and indexation
- Logs reveal the crawl queue in action. If bots rarely reach certain URLs, those pages often index poorly. Read more on crawlability.
- When canonicals, robots rules, and sitemaps disagree, logs show which directive actually influenced behavior. See How Google Search Works.
Quick comparison
- Crawl data: A simulated visit that spots technical issues but can’t confirm how bots behave in the wild.
- Log data: The ground truth for bot behavior on your server.
- Google Search Console: Useful summaries for page indexing and crawl stats, with limited line-by-line crawl detail. Use the URL Inspection tool to verify individual URLs.
Search engine crawling
Here’s the short version of how search engines work with your site. Bots discover URLs from internal links, sitemaps, external links, and their own history. They add URLs to a queue, request the page, receive a response, and decide whether to render. If the content depends on JavaScript, they might do a second pass to render. They respect robots.txt rules, consider canonical tags, and store signals for ranking. For an overview, see How Google Search Works.

Where logs see this
- Discovery. You’ll notice hits to robots.txt and your XML sitemaps. You’ll also see referrers from internal pages that pass link equity. See Your guide to sitemaps.
- Fetch. Every request to a URL lands in your logs, including HTML, CSS, JS, images, and APIs.
- Render. If your site uses heavy JavaScript, you’ll see repeated requests to JS bundles and APIs. Consider JavaScript SEO.
- Revisit. Priority pages get crawled more often. Logs show the cadence by URL and by bot type, including Googlebot Smartphone, the primary crawler for most sites.
Signals that drive crawl frequency
- Internal links. Strong links from high-traffic hubs lift crawl rate for target pages. See guidance on internal linking structure.
- Sitemaps. Fresh, accurate lastmod dates invite faster recrawls.
- External links. New mentions often lead to quick discovery.
- Freshness. Pages that change often get checked more often.
- Site health. Fewer errors, faster responses, and clean directives build trust.
Access log files
You can get logs from several sources. The key is to keep them raw, complete, and retained long enough to see trends.
Where to pull logs
- Web servers. NGINX and Apache store access logs by default. Ensure user agent and host fields are included.
- CDNs. Edge logs can stream to storage buckets for analysis. For Cloudflare, see Logpush.
- Load balancers. Check managed services for request logs.
- Hosting panels. Many hosts allow raw access log downloads.
Collection tips
- Request raw access logs and confirm fields include timestamp, method, URL, status, bytes, user agent, referrer, and host.
- Retain 30 to 90 days. Less than a month makes trend analysis shaky.
- Centralize storage. A single bucket or repository keeps files consistent.
Processing steps
- Deduplicate across edge and origin. CDNs can double count unless you filter properly.
- Normalize time zones. Pick UTC and stick to it.
- Filter by host if you run multiple sites on one server.
- Sample only when volumes are huge and you understand the margin of error.
Verify bots
- Confirm Googlebot and Bingbot via reverse DNS lookups and forward resolutions. Don’t rely on user agent strings alone - spoofing is real. Reference Google’s crawler docs on how bots can change their behavior.
Analysis options
- Use a dedicated log analyzer, a search or analytics platform, or a data warehouse pipeline - whatever gives you query flexibility, bot filters, and joins with your URL lists. Examples: Screaming Frog’s log analyzer, log analyzer tool, and log analysis tools.
- Pair logs with Google Search Console’s page indexing and crawl stats to connect crawl behavior to indexing outcomes. For verification and troubleshooting, use the URL Inspection tool.
- For scalable workflows, see this guide on using Python and Google Cloud for scalable log insights.
Crawl budget insights
Log data can read like alphabet soup. Turn it into a few high-value views that answer clear questions for B2B leaders.

Analyses that pay off
- Crawler mix and trend by bot. See how Googlebot Smartphone compares to desktop and Bingbot week over week. A sudden drop can flag a technical issue. Background: technical SEO issues.
- Status code waste. Count bot hits to 404s, 410s, and 5xx responses. Fixing this waste moves your KPIs fast.
- Non-indexable pages getting crawled. If noindex pages or canonicalized variants receive heavy crawl, you’re burning budget.
- Orphan and unlinked URLs. Logs reveal URLs bots found that your crawler can’t reach. Decide to remove, redirect, or reintegrate.
- Crawl distribution by template. Compare service pages, case studies, blog posts, and resources. Money pages should own the majority of crawl share.
- Days since last crawl for priority pages. If it’s been weeks, add internal links and refresh sitemaps.
- Crawled but not indexed. Cross-reference logs with the Page indexing report in Search Console. If bots visit a URL but it never indexes, check quality, duplication, and directives. Use URL Inspection tool.
- Parameter and pagination traps. Look for recurring patterns like ?sort= or ?page=. Decide which to allow, canonicalize, or block from crawling.
- JavaScript rendering gaps. If bots pull lots of JS but rarely fetch HTML for certain sections, consider server-side rendering or lighter JS for those pages. See JavaScript SEO.
- Optional. LLM and AI bot exposure. Track GPTBot, GoogleOther, and ClaudeBot. Decide whether to allow, block, or throttle in robots.txt and at the firewall. Industry context: Cloudflare’s Pay Per Crawl.
Useful KPIs to put on one screen
- Crawl share by template and by priority page list.
- Error hit rate and its trend line.
- Days to first discovery for new URLs, measured by the first Googlebot hit in logs.
- Percent of bot hits to non-indexable pages.
- Average response time for pages bots crawl most.
Act on log insights
Data without moves is just trivia. Turn each finding into a fix that stresses clarity and speed.
- Crawl traps and loops. Disallow patterns like /search, /calendar, and endless parameters in robots.txt; reduce internal links that feed the trap; use rel=canonical or noindex where content must exist. Note: robots.txt stops crawling, not indexing from external links - use noindex for definitive deindexing. Reference: Robot.txt SEO: Best Practices, Common Problems & Solutions.
- Thin or low-value templates. Use noindex and reduce internal link flow into those sections. If you keep them, improve content quality and link them purposefully to core pages.
- Duplicate URLs. Consolidate with 301s. Make the canonical path match your internal links and sitemaps. Keep one URL per page, including protocol and host.
- Canonical corrections. If canonicals disagree with sitemaps or internal links, pick a single source of truth and update all three to match.
- Sitemap pruning and lastmod. Drop non-indexable URLs and stale variants. Add accurate lastmod to priority pages to speed up recrawls after updates.
- Redirect chains. Shorten 301 chains to a single hop. Chains waste crawl time and bleed link signals.
- Server fixes for 5xx and timeouts. Improve stability and consider caching headers (ETag or Last-Modified) for URLs bots visit most. Slow or flaky pages chew through crawl minutes.
- Migrations and big releases. Compare pre- and post-release logs to catch missed redirects, blocked paths, and spikes in errors. Keep a watch list of legacy top pages for the first few weeks. Deep dive: website migration.
Internal linking
Internal links are your crawl accelerator. Logs show which hubs bots love, so use those hubs to power money pages. See internal linking structure and practical tactics like 4 Ways to Optimize Your Crawl Budget with Internal Links.
- Identify under-crawled money pages. If a service page sees few bot hits, give it links from your header, footer, and service hubs.
- Strengthen anchors. Use concise anchors that match intent. Replace vague “Learn more” with the service and problem it solves.
- Breadcrumbs and consistent paths. Breadcrumbs help bots and users understand structure. Keep them consistent and click-friendly.
- Surface recrawl. Link fresh or updated pages from high-crawl hubs like the homepage, the main services list, and the sitemap index.
- Show the change. Track crawl share to target pages before and after link changes. You want a clear lift.
Log file limitations
As useful as logs are, they’re not perfect. Keep these realities in mind, plus ways to handle them.
- Partial coverage through CDNs. If a CDN serves most assets, origin logs may miss those hits. Use edge logs or combine sources to fill gaps.
- Missing logs in some stacks. Certain managed platforms limit raw access. Ask for exports or use built-in analytics that include bot data.
- Privacy and redaction. Confirm you’re not storing PII. Many teams mask IPs or drop referrers for sensitive paths.
- Bot spoofing. User agent strings can be faked. Verify Googlebot and Bingbot with reverse DNS lookups, and if needed, IP checks against Google’s published ranges.
- HEAD vs GET. Some bots use HEAD to check freshness. Count both, and don’t confuse HEAD spikes with full crawls.
- Staging bleed. Make sure staging and production don’t share logs or sitemaps. Accidental exposure confuses crawl signals.
- Sampling bias. If you sample due to volume, document the method. For small sites, avoid sampling when possible.
- Pair with other sources. Logs tell you what bots fetched. Use Search Console for page indexing and crawl stats, and run a site crawler to find broken links and directive mismatches at scale. Helpful context on Logs expose server-side and technical issues and Your guide to sitemaps.
A quick closing thought. You might think log work is only for massive sites. Fair point. But B2B service companies win with precision. You have a short list of URLs that matter, and you need search engines to find, recrawl, and trust those URLs. Log file analysis for SEO gives you a clear view. It’s not flashy. It’s not guesswork. It’s a rhythm of small technical wins that keep your pipeline healthy without adding noise. And that’s the kind of quiet efficiency worth investing in. If you want a deeper checklist to get started, try this Log File Analysis checklist.



.svg)

.svg)
.svg)