
Google announced DS-STAR, a data science agent, on November 6, 2025, via a Google Research announcement. Authored by Jinsung Yoon and Jaehyun Nam of Google Cloud, the release includes an arXiv Paper detailing design and evaluations across multiple benchmarks.
What DS-STAR does
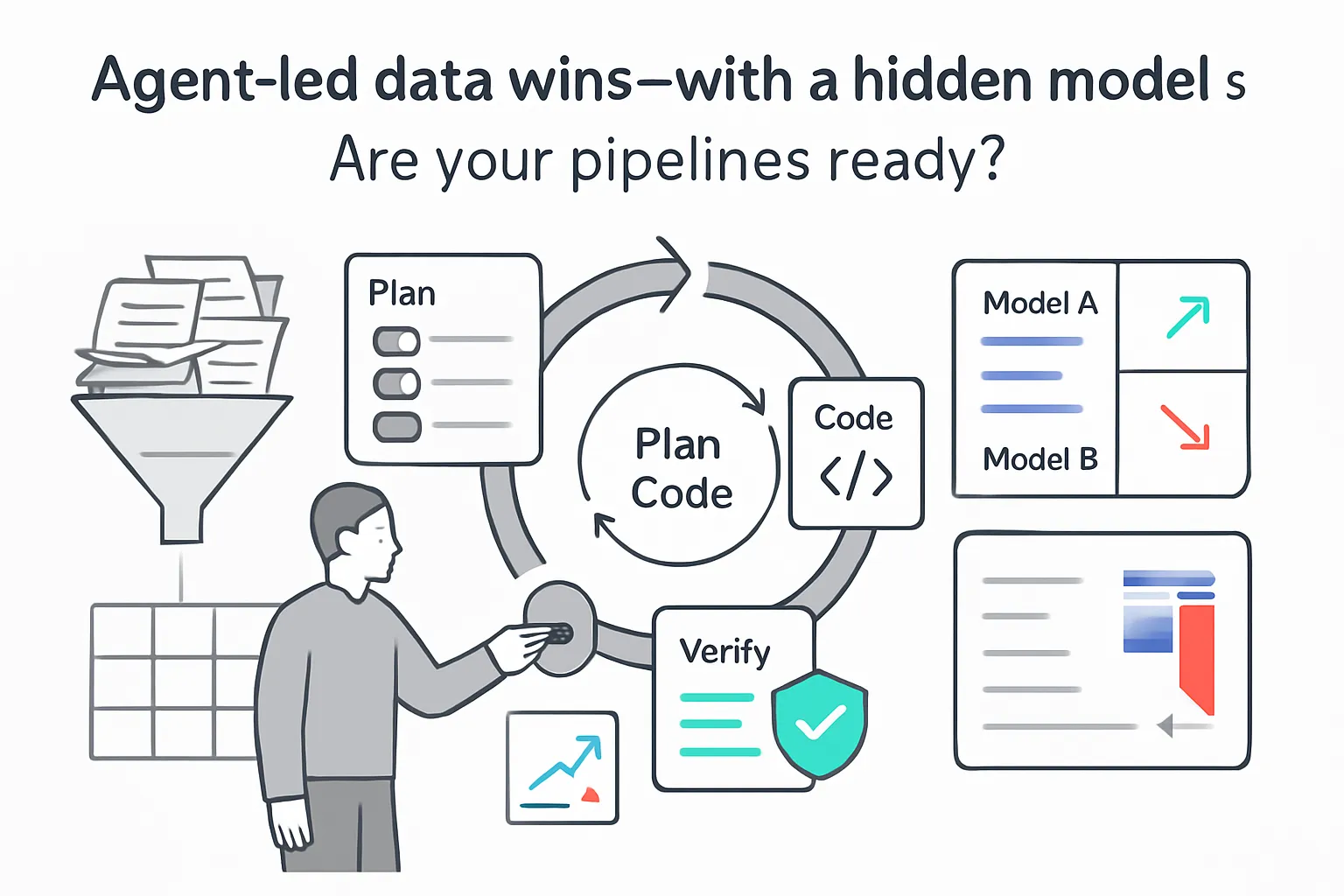
DS-STAR targets practical data science tasks across heterogeneous files and open-ended requests. It automates statistical analysis, visualization, and data wrangling, then verifies results step by step.
- Two-stage workflow: a file analyzer followed by an iterative plan-code-verify loop.
- The analyzer summarizes directory contents across formats like JSON, unstructured text, and Markdown.
- Four agents coordinate work: Planner, Coder, Verifier, and Router.
- The Verifier is an LLM-based judge that checks whether the plan and intermediate outputs are sufficient.
- Plans are revised by adding or correcting steps based on verifier feedback.
- The process mirrors notebook-style workflows with review of intermediate results, similar to Google colab.
- Execution stops after 10 rounds or when the plan is approved.
- Outputs can include trained models, processed databases, visualizations, or text responses.
Results at a glance
- On DABStep, accuracy improved from 41.0% to 45.2%.
- On KramaBench, accuracy increased from 39.8% to 44.7%.
- On DA-Code, accuracy moved from 37.0% to 38.5%.
- DS-STAR ranked first on the DABStep public leaderboard as of September 18, 2025.
- Ablations: removing the analyzer dropped accuracy on hard DABStep tasks to 26.98%. Removing the Router reduced results on both easy and hard tasks.
- Comparisons included baselines such as AutoGen and DA-Agent.
Model choices
Tests used different LLMs, including GPT-5 and Gemini-2.5-Pro. According to the post, GPT-5 performed better on easy tasks, while Gemini 2.5 Pro performed better on hard tasks.
Why it matters
Businesses depend on data-driven insights and increasingly need tools that handle messy, multi-file workflows. Recent recent research and continued progress show LLM-based agents can translate natural language into executable analysis. Benchmarks such as DABStep emphasize heterogeneous data formats, and many data science problems lack ground-truth labels, which motivates DS-STAR's verification loop.






.svg)

.svg)
.svg)