
Google's Search Relations team warned that generic login pages can disrupt indexing and surface login screens in Search results. In a recent Search Off the Record podcast episode, John Mueller and Martin Splitt explained how duplicate clustering, robots.txt limits, noindex, redirects, and paywalled structured data apply.
Why generic login pages get indexed
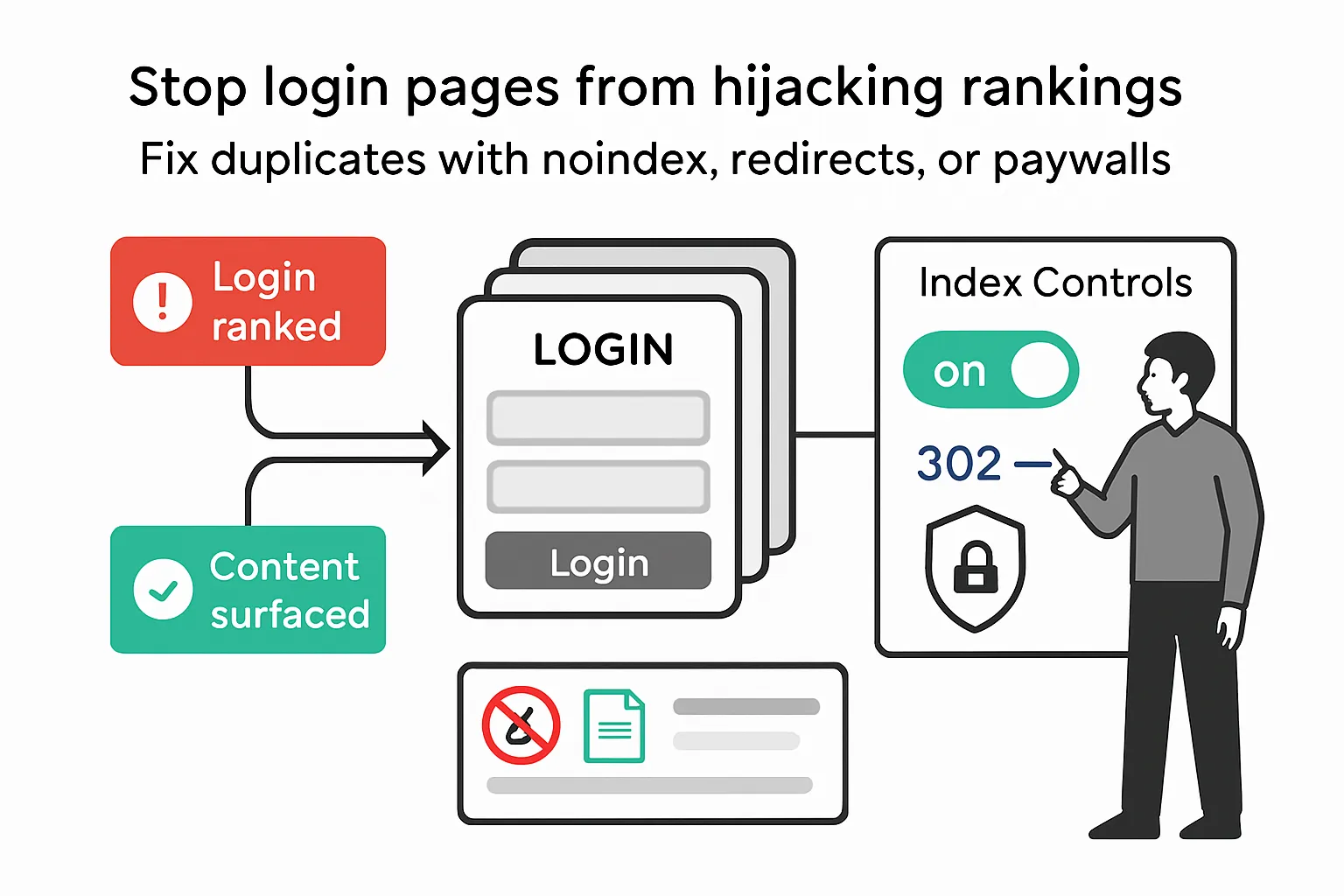
When multiple private URLs render the same minimal login screen, Google may treat those URLs as duplicates and index the login page instead. Mueller said Google can fold such URLs into a single cluster that uses the login screen as the representative result, and noted teams inside Google have seen similar issues.
"Put some information about what your service is on that login page."
Short login pages provide little indexable context. If many URLs lead to the same screen, the login page can appear in Search where content pages are expected.

What Google recommends
- Do not rely on robots.txt alone - blocked URLs can still be indexed without snippets. See the robots.txt overview.
- For private areas, use the noindex robots directive or redirect to a login page.
- Avoid loading private text in the DOM and hiding it with JavaScript.
- To index restricted content appropriately, add paywalled content structured data. Mueller said this markup can apply to login or similar access controls and helps avoid cloaking misclassification.
- Understand how Google consolidates duplicates and selects canonicals - see duplicate URL consolidation guidance.
Context
The discussion from Google Search Relations covered duplicate handling, noindex, redirects, and paywalled markup in detail on the Search Off the Record episode.






.svg)

.svg)
.svg)