
Google Research introduced "speculative cascades," a hybrid method to speed up large language model inference, announced on September 11, 2025 on the Google Research blog by research scientists Hari Narasimhan and Aditya Menon. The accompanying arXiv paper is titled "Faster Cascades via Speculative Decoding."
What is new
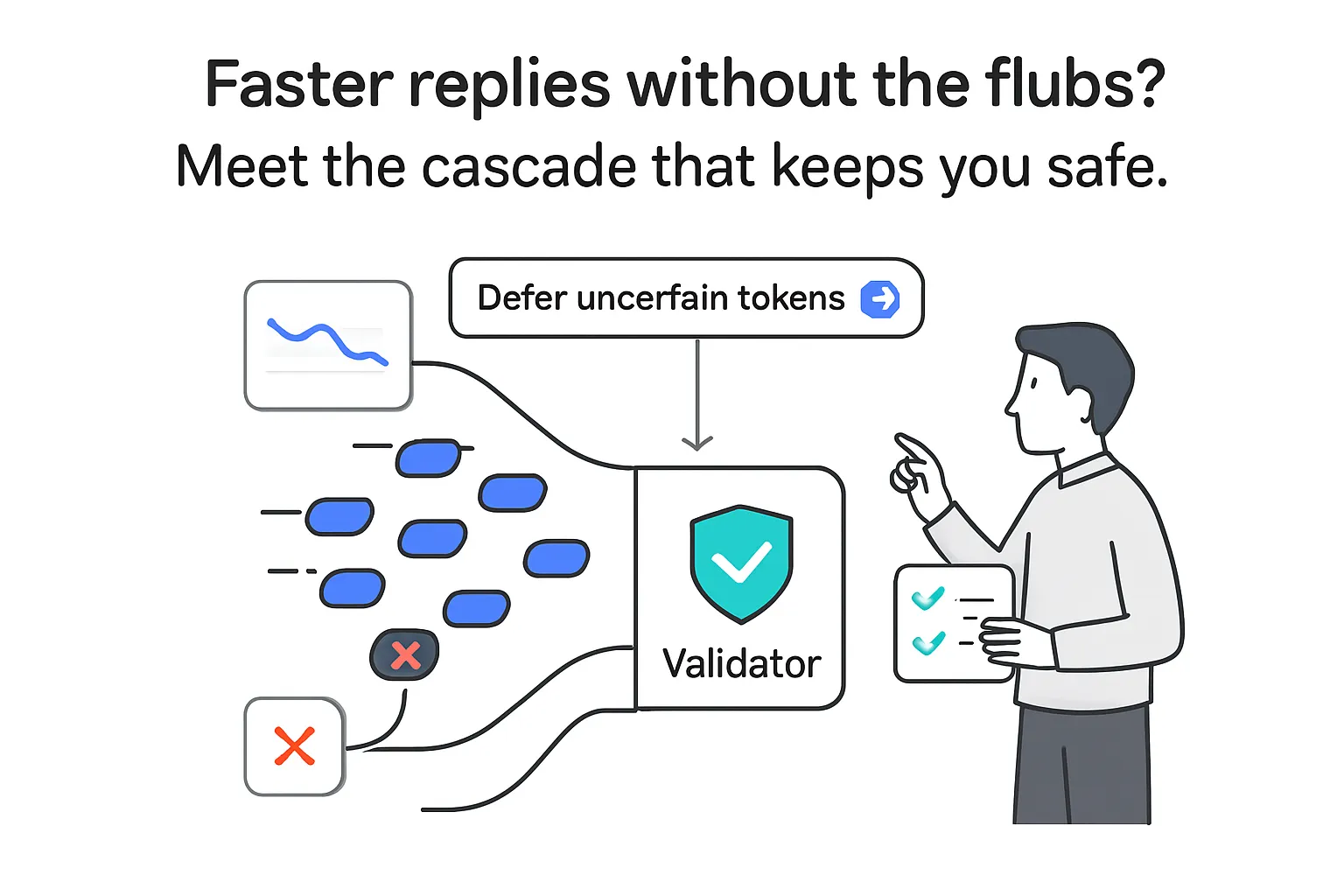
Speculative cascades combine two established approaches in a single inference flow: a small drafter model runs alongside a larger target model, and a flexible deferral rule decides token-by-token whether to accept the small model's draft or defer to the large model. According to Google, this setup delivers better cost-quality trade-offs and higher speed-ups than using standard cascades or speculative decoding alone.
How speculative cascades work
The system drafts tokens with a small model and evaluates them against the large model's scores using a deferral rule. If the criteria are met, the draft token is accepted. If not, the method defers to the large model for that token. This preserves parallelism while reducing unnecessary large-model work.
Deferral options
- Confidence-based checks
- Comparative score checks between models
- Cost-benefit checks that weigh latency and quality
- Top-k list consistency checks
Background
In cascades, a smaller model handles easy queries and defers harder cases to a larger model, reducing compute but adding sequential latency when deferrals occur. Speculative decoding runs a small model in parallel with a large model, verifying drafted tokens for lower latency, but strict token matching can reject valid drafts that differ in wording. Speculative cascades replace strict verification with a scoring-based deferral rule, aiming to keep parallelism without the sequential bottlenecks of traditional cascades.
Performance and benchmarks
The authors report higher speed-ups at similar quality across tested tasks and improved tokens per large-model call at fixed quality. Benchmarks span summarization, translation, reasoning, coding, and question answering. Visuals in the blog and paper include trade-off curves, block diagrams, and a GSM8K example.
Experiments used the Gemma and T5 model families. For reasoning, the work references the GSM8K dataset.
Why it matters
For teams deploying LLMs, speculative cascades target lower latency and cost by reducing unnecessary large-model computation while maintaining quality. The token-level deferral rule offers a tunable control to hit specific cost, speed, or quality targets.
Contributors
Blog authors: Hari Narasimhan and Aditya Menon. Additional credits: Wittawat Jitkrittum, Ankit Singh Rawat, Seungyeon Kim, Neha Gupta, and Sanjiv Kumar. Acknowledgements: Ananda Theertha Suresh, Ziteng Sun, Yale Cong, Mark Simborg, and Kimberly Schwede.
Sources
- Google Research blog announcement - September 11, 2025
- arXiv: Faster Cascades via Speculative Decoding






.svg)

.svg)
.svg)