
Testing LLMs on superconductivity research questions: why curated sources beat open-web LLMs
Large language models (LLMs) are marketed as research assistants, but most validation still focuses on generic benchmarks and surface-level tasks. A recent physics case study offers harder evidence: when experts asked LLMs sophisticated questions about high-temperature superconductors, models connected to curated literature clearly outperformed general web-connected systems. The findings have direct implications for any business using LLMs on specialized, high-stakes topics.
Testing LLMs on superconductivity research questions
This report summarizes a Google - Cornell University - Harvard study on how six LLMs handled 67 expert-level questions in condensed-matter physics, and extracts lessons for designing reliable AI research tools in specialized domains.
Executive snapshot: LLM accuracy on high-Tc superconductivity questions
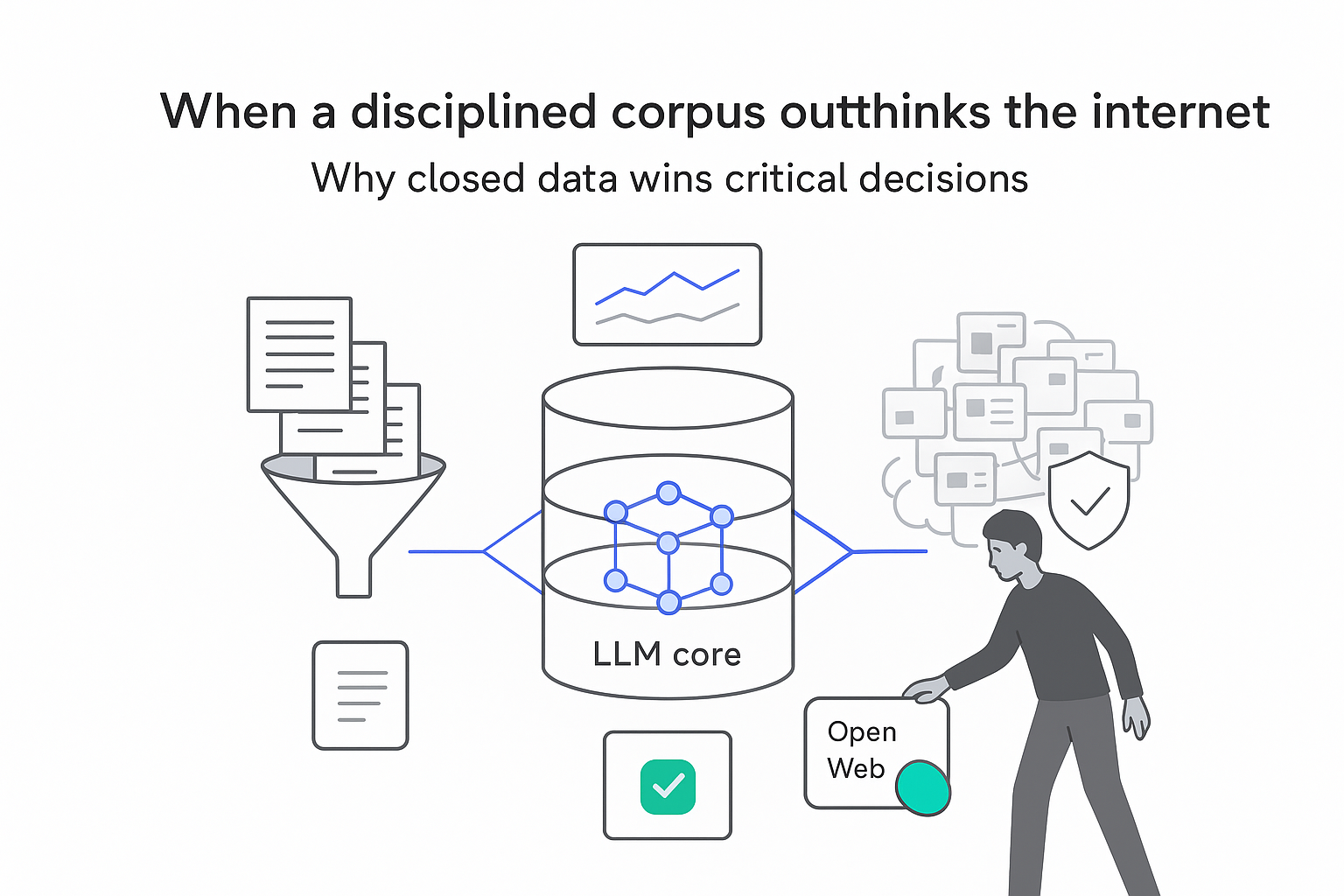
- Six LLMs were tested on 67 expert-written questions about high-temperature superconductors (cuprates), covering mechanisms, evidence and competing theories in an active research area [S1, S2].
- Two systems using a closed, curated corpus of 1,726 physics papers and reviews - NotebookLM and a custom retrieval-augmented system - scored highest across expert ratings for balance, comprehensiveness and evidencing [S1, S2].
- Four LLMs with full web access (including 765 open-access experimental and 1,553 theoretical cuprate papers) more often mixed speculative ideas with well-established results and omitted key evidence [S1].
- All models showed weaknesses in temporal reasoning, such as failing to track when hypotheses were later ruled out, and in using tables and figures beyond their captions [S1].
- Expert scoring used a masked setup with 12 international superconductivity specialists, who graded each response 0 - 2 on six dimensions including balance, evidence and concision [S1, S2].
Implication for marketers: for specialized or regulated topics, LLMs grounded in vetted internal or curated content are likely safer and more reliable than generic, open-web chatbots.
Method and source notes on LLMs in condensed-matter physics
The study evaluated whether LLMs can act as knowledgeable, neutral partners on cutting-edge questions in high-temperature superconductivity, focusing on cuprate materials where the mechanism of superconductivity remains unresolved [S1, S2].
What was measured
- Task: answer 67 expert-designed questions that probe deep understanding of high-Tc superconductors (for example, specific doping levels for phase transitions and evidence for quantum critical points) [S1].
- Models: six LLM-based systems - GPT-4o, Perplexity, Claude 3.5, Gemini Advanced Pro 1.5, NotebookLM, and a custom retrieval-augmented system built by the researchers [S1].
- Experts: 12 senior researchers in high-temperature superconductivity from institutions including Stanford, Johns Hopkins, MIT, Cornell, Harvard and others [S1].
- Scoring: masked review (experts did not know which model produced which answer), using a 0 - 2 scale on:
- Balanced perspective
- Comprehensiveness
- Conciseness
- Evidence and references
- Visual relevance (for the two models that routinely used images)
- Open-ended qualitative feedback [S1, S2]
Data sources for the LLMs
- Closed, curated systems (2 models):
- 15 expert-selected review articles summarizing high-Tc superconductivity [S1].
- Approximately 3,300 references extracted from those reviews, filtered using Gemini to 1,726 sources (review and experiment-based papers) that fed NotebookLM and the custom system [S1].
- Web-connected systems (4 models):
- Full internet access, including 765 open-access experimental and 1,553 theoretical cuprate papers identified from the same reference pool [S1].
Timing and limitations
- Models were accessed and evaluated in December 2024. Capabilities of named products may have changed since [S1].
- The question set and evaluation rubric were specific to condensed-matter physics, which limits direct generalization to other domains.
- Quantitative score distributions by model were not fully disclosed in the blog summary; reported findings are primarily relative (which models did better on which metrics) rather than exact numbers [S1].
Sources used in this report
- [S1] Venugopalan & Kim, Testing LLMs on superconductivity research questions, Google Research Blog, March 16, 2026 (summary of the study and related Google work).
- [S2] Venugopalan et al., Expert evaluation of LLM world models: A high-Tc superconductivity case study, published in the Proceedings of the National Academy of Sciences. Open access Paper.
Findings: performance of curated vs web-connected LLMs
The supervised comparison yielded several consistent patterns across the six models.
Closed, curated systems outperformed web-connected LLMs
- Google NotebookLM, configured to answer only from the curated library of 1,726 physics sources, achieved the highest overall expert scores among the six systems [S1].
- A custom system based on retrieval-augmented generation built by the research team on the same curated library was the second-best overall performer [S1].
- These two curated systems consistently ranked in the top three for:
- Balanced treatment of competing theories
- Comprehensiveness of answers
- Quality and quantity of supporting references [S1]
- NotebookLM was the least concise but scored highest on evidence provision, suggesting that experts preferred longer answers when they were strongly grounded in citations [S1].
Web-connected models showed more mixing of strong and weak evidence
- LLMs with broad internet access often blended widely accepted theories with fringe or highly speculative ideas without clearly labeling which was which [S1].
- These models were more likely to omit key experiments or papers when the question phrasing did not closely match the terminology used in the literature, indicating limitations in recall and retrieval [S1].
Visual reasoning and use of figures remain fragile
- Only two models regularly generated or referenced images in their answers; for those, experts assessed visual relevance [S1].
- Across the board, image-related scores were lower than text-based metrics, and models often appeared to rely on captions rather than genuine interpretation of plots, data tables or scale bars [S1].
Temporal and contextual understanding is unreliable
- All systems showed weaknesses in tracking the evolution of scientific consensus over time [S1].
- In several cases, models repeated early hypotheses about cuprate superconductivity without acknowledging later results that challenged or falsified those ideas [S1].
- This affected the balance and accuracy metrics, since experts expected answers to distinguish between current consensus and outdated proposals.
Positioning within broader LLM-science work
- The superconductivity study builds on prior Google efforts such as a cross-disciplinary scientific problem-solving suite, CURIE, which evaluated whether LLMs could perform basic analytic tasks in several scientific fields [S1].
- Related work has used LLMs to interpret tables and figures, solve equations in quantum mechanics, and solve engineering simulation problems via specialized software [S1].
- Other Google groups are experimenting with LLMs as hypothesis generators, scientific software authors and a model for single-cell analysis in cancer research [S1].
Overall, the superconductivity case shows that how an LLM is grounded - curated corpus vs open web - meaningfully changes performance on expert-level questions, even when base model quality is strong.
Interpretation and implications for marketers using LLM research tools
Curated corpora are likely safer for specialized domains
- The strong showing of NotebookLM and the custom retrieval-augmented system suggests that LLMs constrained to a high-quality, vetted corpus can outperform more flexible web-connected models on complex, contested topics [S1].
- For businesses dealing with regulated content (finance, health, law, technical B2B products), this supports investing in:
- Curating an internal knowledge base (manuals, white papers, reports, compliance documents).
- Using retrieval-augmented LLMs that answer only from that base, with clear citations.
Citation-rich answers beat short, unsupported summaries
- Experts favored NotebookLM's more verbose but better-referenced responses over shorter, less-grounded ones [S1].
- For marketing and research workflows, this points toward citation-friendly LLM outputs (with links to internal documents, past campaigns, case studies or data sources) as more trustworthy than terse, reference-free answers.
Temporal reasoning gaps are a real risk for changing topics
- The models' difficulty with hypotheses that were later overturned illustrates a general issue: LLMs may confidently present outdated information when the field changes quickly [S1].
- For marketers, similar risks exist around:
- Fast-moving regulations (privacy, AI, sector-specific rules)
- Platform changes (ad policies, algorithm updates)
- Product or pricing history
- Mitigation strategies include time-stamped retrieval (for example, "only show content from the last 12 months") and periodic human review of answers on time-sensitive topics.
Visual analytics and dashboards should not rely solely on LLMs yet
- Since models largely leaned on figure captions rather than interpreting plots, their ability to read complex dashboards, charts or CRO test results may be limited [S1].
- LLMs can still help with explanations of already-summarized metrics, but businesses should be cautious about using them to draw new quantitative conclusions from raw charts or tables without human oversight.
Evaluation needs domain experts and realistic questions
- The superconductivity study relied on 12 specialists constructing and grading 67 challenging questions [S1, S2].
- For businesses planning to roll out LLM tools internally, this suggests that simple "does this answer look good?" checks are insufficient. A stronger approach is:
- Ask domain experts (legal, compliance, product, analytics) to write test questions that mirror real decisions.
- Score responses on balance, completeness, citation quality and concision, not just style or tone.
Contradictions and gaps in current LLM evaluations
Scope and generalizability
- The study covers a single, highly technical domain (high-Tc superconductivity). It is not yet shown that the same performance ordering (NotebookLM > custom curated system > others) holds in fields like medicine, law or finance. Any extension to those areas is speculative.
Limited transparency on detailed scores
- The blog summary reports relative rankings and high-level patterns (who scored best on which metric) but not full score distributions or statistical tests [S1]. This constrains how finely one can compare individual models.
Model versions and future updates
- All evaluations were conducted in December 2024 [S1]. LLMs evolve rapidly, so absolute performance levels and even relative rankings may shift. Applying these findings to present-day model versions is tentative.
Question set design bias
- The 67 questions were written by experts deeply embedded in the high-Tc community [S1]. That strengthens relevance, but may embed specific assumptions about what "good understanding" looks like.
- There is limited information in the summary on how diverse the questions were across subtopics or viewpoints; this is another tentative limitation.
Future evaluations
- The authors mention an upcoming condensed-matter-theory evaluation, the CMT-benchmark, to be presented at ICLR 2026, aimed at broader and more rigorous testing of LLMs on theoretical physics tasks [S1]. Details are not yet public in the summary, so its eventual design and findings remain unknown.
Data appendix: key numbers from the superconductivity LLM study
- LLMs tested: 6 (GPT-4o, Perplexity, Claude 3.5, Gemini Advanced Pro 1.5, NotebookLM, custom curated retrieval-augmented system) [S1].
- Expert evaluators: 12 international high-Tc superconductivity specialists [S1].
- Questions: 67 expert-written prompts targeting mechanisms, evidence and competing theories in high-Tc superconductivity [S1].
- Curated corpus construction:
- 15 expert-selected review articles [S1].
- Approximately 3,300 references extracted from those reviews [S1].
- 1,726 sources (reviews and experiment-based papers) used as the closed corpus for NotebookLM and the custom system [S1].
- Open-web corpus available to web models:
- 765 open-access experimental cuprate papers [S1].
- 1,553 open-access theoretical cuprate papers [S1].
- Scoring scale: 0 (bad), 1 (ok), 2 (good) across balance, comprehensiveness, conciseness, evidence and visual relevance (for image-using models), plus qualitative feedback [S1, S2].
These structured results point to a consistent theme: careful curation and grounded retrieval matter at least as much as raw LLM horsepower when answers must stand up to expert scrutiny.






.svg)

.svg)
.svg)