
Reddit has filed a federal lawsuit in New York accusing Perplexity and three partners of bypassing access controls to obtain Reddit content, according to a newly filed complaint. The filing alleges large-scale copying, including access via Google search results. Perplexity posted a public response on Reddit saying it summarizes discussions with citations and does not use Reddit content to train its models.

Perplexity Responds To Reddit Lawsuit Over Data Access
The complaint names Perplexity, Oxylabs UAB, AWMProxy, and SerpApi, describing the latter companies as intermediaries that helped obtain Reddit content. Perplexity denies training on Reddit content and says it cites threads in answers, per its public response.
"We summarize Reddit discussions, and we cite Reddit threads in answers."
"We won't be extorted, and we won't help Reddit extort Google."
Perplexity also says it does not use Reddit content to train its models.
Key Details
- Reddit filed the suit in New York federal court, according to the complaint.
- Reddit alleges Perplexity used SerpApi to access Reddit content through Google search results.
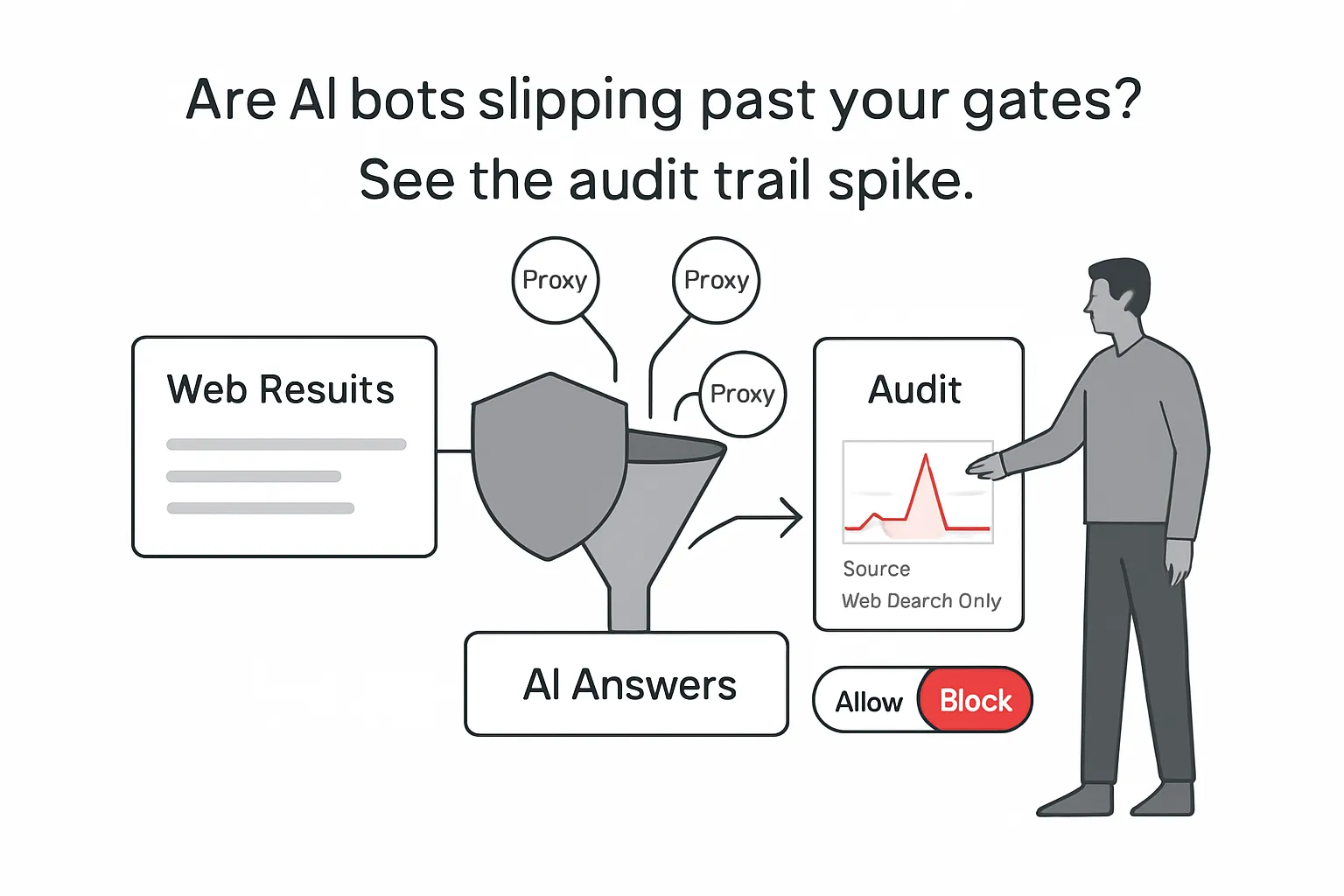
- The filing says a test post crawlable only by Google appeared in Perplexity results within hours.
- Reddit alleges Perplexity citations to Reddit rose roughly forty-fold after a cease-and-desist letter.
- Oxylabs UAB and AWMProxy are named as additional intermediaries that facilitated data access.
- Perplexity says it summarizes Reddit discussions with citations and does not train its models on Reddit content, per its public response.
Background and Related Reporting
Cloudflare said it observed "stealth, undeclared crawlers" that ignored no-crawl directives in tests run in August.
Separately, Wired reported that Perplexity used undisclosed IPs and spoofed user-agent strings to bypass robots.txt, and Forbes accused the company of republishing an exclusive and threatened legal action.






.svg)

.svg)
.svg)